微服务架构及raft协议
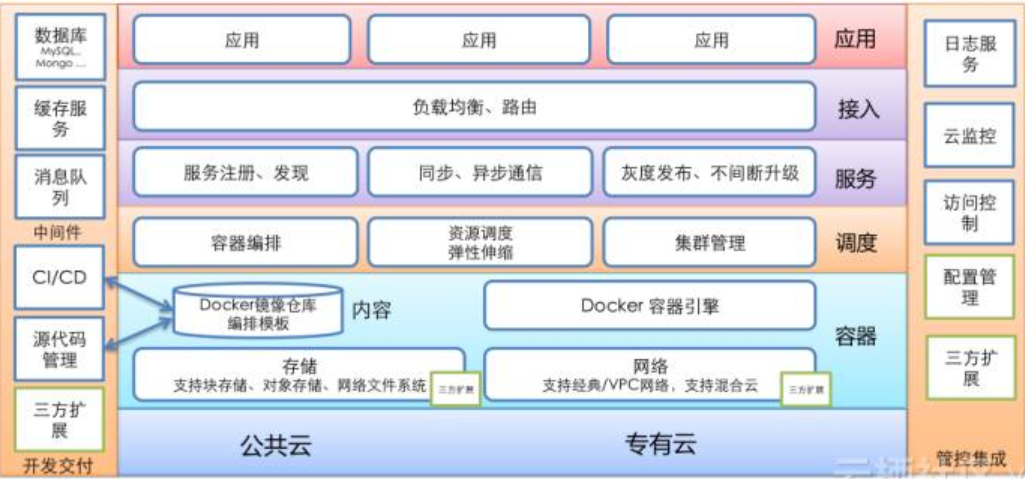
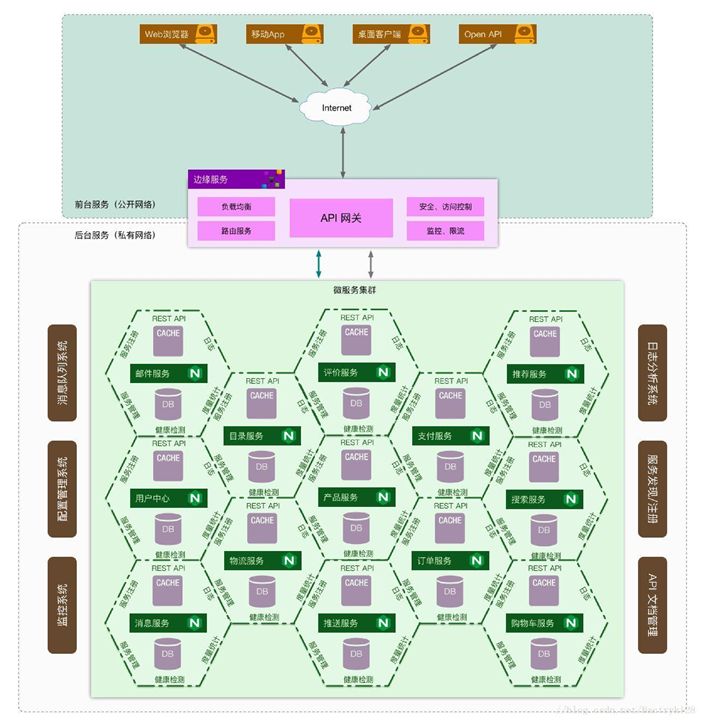
微服务架构全景图
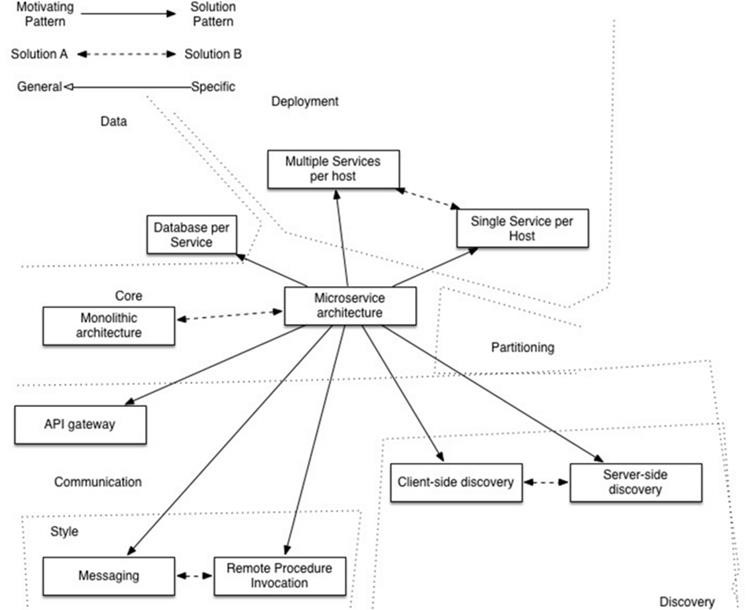
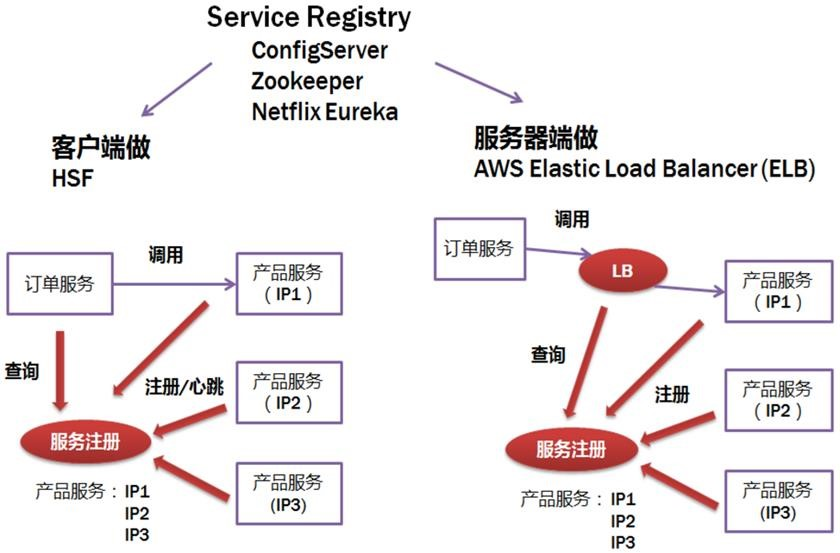
服务注册和发现
Client side implement
- 调用需要维护所有调用服务的地址
- 有一定的技术难度,需要rpc框架支持
Server side implement
- 架构简单
- 有单点故障
注册中心
etcd注册中心
- 分布式一致性系统
- 基于raft一致性协议
etcd使用场景
- 服务注册和发现
- 共享配置
- 分布式锁
- Leader选举
Raft协议详解
应用场景
- 解决分布式系统一致性的问题
- 基于复制的
工作机制
- leader选举
- 日志复制
- 安全性
基本概念
raft协议演示:http://www.kailing.pub/raft/index.html
角色
- Follower角色
- Leader角色
- Candicate角色
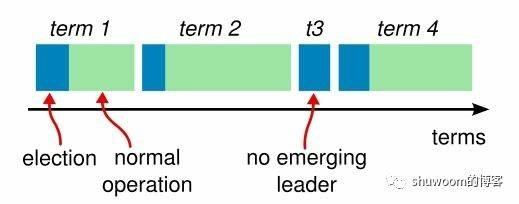
Term(任期)概念
- 在raft协议中,将时间分成一个个term(任期)
复制状态机
在一个分布式系统数据库中,如果每个节点的状态一致,每个节点都执行相同的命令序列,那么最终他们会得到一个一致的状态。也就是和说,为了保证整个分布式系统的一致性,我们需要保证每个节点执行相同的命令序列,也就是说每个节点的日志要保持一样。所以说,保证日志复制一致就是Raf等一致性算法的工作了
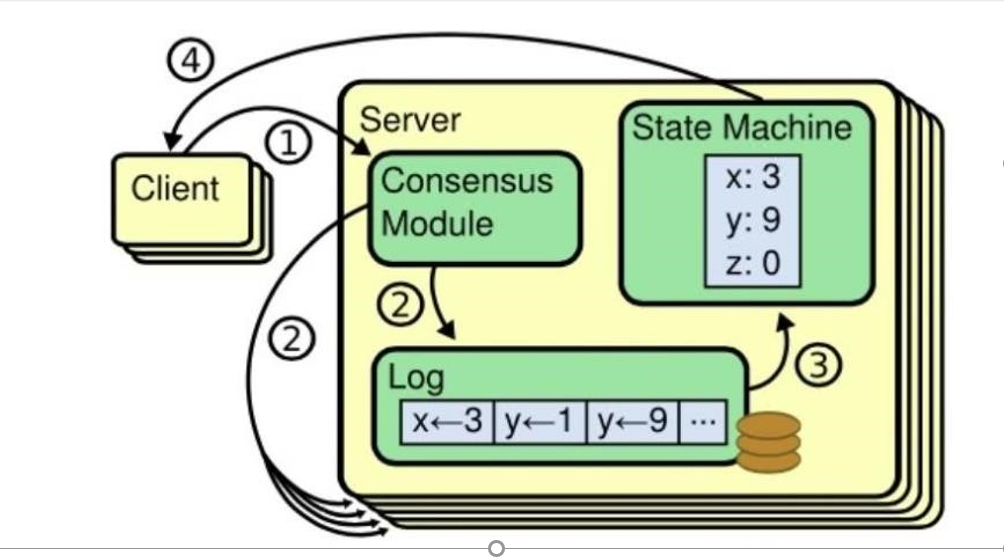
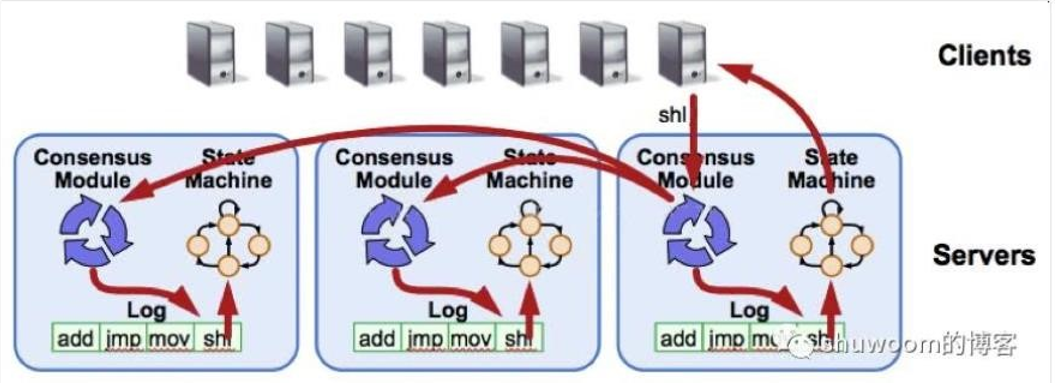
这里就涉及 Replicated State Machine(复制状态机),如上图所示。在一个节点上,一致性模块( Consensus Module,也就是分布式共识算法)接收到了来自客户端的命令。然后把接收到的命令写入到日志中,该节点和其他节点通过一致性模块进行通信确保每个日志最终包含相同的命令序列。一旦这些日志的命令被正确复制,每个节点的状态机( State Machine)都会按照相同的序列去执行他们,从而最终得到一致的状态。然后将达成共识的结果返回给客户端,如下图所示。
心跳(heartbeats)和超时机制(timeout)
在Ra算法中,有两个 timeout机制来控制领导人选举一个是选举定时器( elation timeou):
即 Follower等待成为 Candidate状态的等待时间,这个时间被随机设定为150ms-300ms之间
另一个是 headrbeat timeout:在某个节点成为 Leader以后,它会发送 Append Entries消息给其他节点,这些消息就是通过 heartbeat timeout来传送, Follower接收到 Leader的心跳包的同时也重置选举定时器
Leader选举
Raft 的选举过程
Raft 协议在集群初始状态下是没有 Leader 的, 集群中所有成员均是 Follower,在选举开始期间所有 Follower 均可参与选举,这时所有 Follower 的角色均转变为 Condidate, Leader 由集群中所有的 Condidate 投票选出,最后获得投票最多的 Condidate 获胜,其角色转变为 Leader 并开始其任期,其余落败的 Condidate 角色转变为 Follower 开始服从 Leader 领导。这里有一种意外的情况会选不出 Leader 就是所有 Condidate 均投票给自己,这样无法决出票数多的一方,Raft 算法为了解决这个问题引入了北洋时期袁世凯获选大总统的谋略,即选不出 Leader 不罢休,直到选出为止,一轮选不出 Leader,便令所有 Condidate 随机 sleap(Raft 论文称为 timeout)一段时间,然后马上开始新一轮的选举,这里的随机 sleep 就起了很关键的因素,第一个从 sleap 状态恢复过来的 Condidate 会向所有 Condidate 发出投票给我的申请,这时还没有苏醒的 Condidate 就只能投票给已经苏醒的 Condidate ,因此可以有效解决 Condiadte 均投票给自己的故障,便可快速的决出 Leader。
选举出 Leader 后 Leader 会定期向所有 Follower 发送 heartbeat 来维护其 Leader 地位,如果 Follower 一段时间后未收到 Leader 的心跳则认为 Leader 已经挂掉,便转变自身角色为 Condidate,同时发起新一轮的选举,产生新的 Leader。
Raft 的数据一致性策略
Raft 协议强依赖 Leader 节点来确保集群数据一致性。即 client 发送过来的数据均先到达 Leader 节点,Leader 接收到数据后,先将数据标记为 uncommitted 状态,随后 Leader 开始向所有 Follower 复制数据并等待响应,在获得集群中大于 N/2 个 Follower 的已成功接收数据完毕的响应后,Leader 将数据的状态标记为 committed,随后向 client 发送数据已接收确认,在向 client 发送出已数据接收后,再向所有 Follower 节点发送通知表明该数据状态为committed。
Raft 如何处理 Leader 意外的?
- client 发送数据到达 Leader 之前 Leader 就挂了,因为数据还没有到达集群内部,所以对集群内部数据的一致性没有影响,Leader 挂了之后,集群会进行新的选举产生新的 Leader,之前挂掉的 Leader 重启后作为 Follower 加入集群,并同步 Leader 上的数据。这里最好要求 client 有重试机制在一定时间没有收到 Leader 的数据已接收确认后进行一定次数的重试,并再次向新的 Leader 发送数据来确保业务的流畅性。
- client 发送数据到 Leader,数据到达 Leader 后,Leader 还没有开始向 Folloers 复制数据,Leader就挂了,此时数据仍被标记为 uncommited 状态,这时集群会进行新的选举产生新的 Leader,之前挂掉的 Leader 重启后作为 Follower 加入集群,并同步 Leader 上的数据,来保证数据一致性,之前接收到 client 的数据由于是 uncommited 状态所以可能会被丢弃。这里同样最好要求 client 有重试机制通过在一定时间在没有收到 Leader 的数据已接收确认后进行一定次数的重试,再次向新的 Leader 发送数据来确保业务的流畅性。
- client 发送数据到 Leader, Leader 接收数据完毕后标记为 uncommited,开始向 Follower复制数据,在复制完毕一小部分 Follower 后 Leader 挂了,此时数据在所有已接收到数据的 Follower 上仍被标记为 uncommitted,但国不可一日无君,此时集群将进行新的选举,而拥有最新数据的 Follower 变换角色为 Condidate,也就意味着 Leader 将在拥有最新数据的 Follower 中产生,新的 Leader 产生后所有节点开始从新 Leader 上同步数据确保数据的一致性,包括之前挂掉后恢复了状态的 老Leader,这时也以 Follower 的身份同步新 Leader 上的数据。
- client 发送数据到 Leader,Leader 接收数据完毕后标记为 uncommitted,开始向 Follower 复制数据,在复制完毕所有 Follower 节点或者大部分节点(大于 N/2),并接收到大部分节点接收完毕的响应后,Leader 节点将数据标记为 committed,这时 Leader 挂了,此时已接收到数据的所有 Follower 节点上的数据状态由于还没有接收到 Leader 的 commited 通知,均处于 uncommited 状态。这时集群进行了新的选举,新的 Leader 将在拥有最新数据的节点中产生,新的 Leader 产生后,由于 client 端因老 Leader 挂掉前没有通知其数据已接收,所以会向新的 Leader 发送重试请求,而新的 Leader 上已经存在了这个之前从老 Leader 上同步过来的数据,因此 Raft 集群要求各节点自身实现去重的机制,保证数据的一致性。
- 集群脑裂的一致性处理,多发于双机房的跨机房模式的集群。假设一个 5 节点的 Raft 集群,其中三个节点在 A 机房,Leader 节点也在 A 机房,两个节点在 B 机房。突然 A、B 两个机房之间因其他故障无法通讯,那么此时 B 机房中的 2 个Follower 因为失去与 Leader 的联系,均转变自身角色为 Condidate。根据 Leader 选举机制,B 机房中产生了一个新的 Leader,这就发生了脑裂即存在 A 机房中的老 Leader 的集群与B机房新 Leader 的集群。Raft 针对这种情况的处理方式是老的 Leader 集群虽然剩下三个节点,但是 Leader 对数据的处理过程还是在按原来 5 个节点进行处理,所以老的 Leader 接收到的数据,在向其他 4 个节点复制数据,由于无法获取超过 N/2 个 Follower 节点的复制完毕数据响应(因为无法连接到 B 机房中的 2个节点),所以 client 在向老 Leader 发送的数据请求均无法成功写入,而 client 向B机房新 Leader 发送的数据,因为是新成立的集群,所以可以成功写入数据,在A、B两个机房恢复网络通讯后,A 机房中的所有节点包括老 Leader 再以 Follower 角色接入这个集群,并同步新 Leader 中的数据,完成数据一致性处理。