从kratos分析BBR限流源码实现
什么是自适应限流
自适应限流从整体维度对应用入口流量进行控制,结合应用的 Load、CPU 使用率、总体平均 RT、入口 QPS 和并发线程数等几个维度的监控指标,通过自适应的流控策略,让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
核心目标:
- 自动嗅探负载和 qps,减少人工配置
- 削顶,保证超载时系统不被拖垮,并能以高水位 qps 继续运行
限流规则
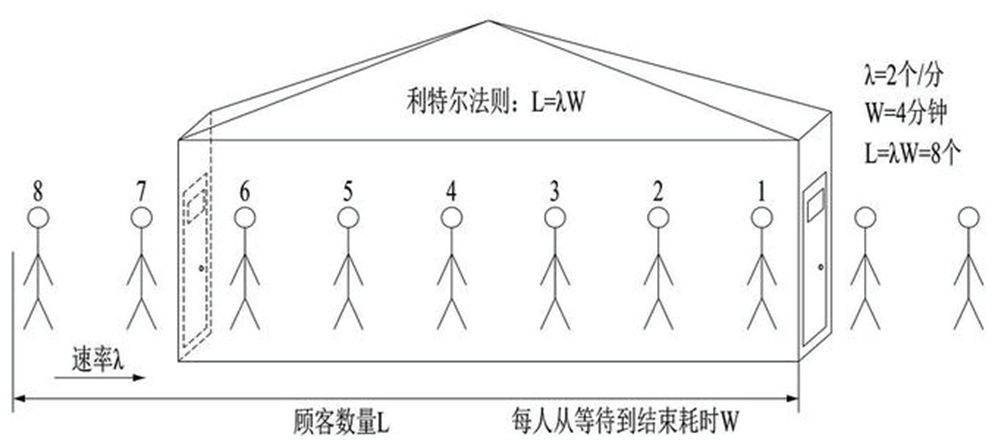
计算吞吐量:利特尔法则 L = λ * W
如上图所示,如果我们开一个小店,平均每分钟进店 2 个客人(λ),每位客人从等待到完成交易需要 4 分钟(W),那我们店里能承载的客人数量就是 2 * 4 = 8 个人
同理,我们可以将 λ 当做 QPS, W 呢是每个请求需要花费的时间,那我们的系统的吞吐就是 L = λ * W ,所以我们可以使用利特尔法则来计算系统的吞吐量。
指标介绍
| 指标名称 | 指标含义 |
|---|---|
| cpu | 最近 1s 的 CPU 使用率均值,使用滑动平均计算,采样周期是 250ms |
| inflight | 当前处理中正在处理的请求数量 |
| pass | 请求处理成功的量 |
| rt | 请求成功的响应耗时 |
滑动窗口
在自适应限流保护中,采集到的指标的时效性非常强,系统只需要采集最近一小段时间内的 qps、rt 即可,对于较老的数据,会自动丢弃。为了实现这个效果,kratos 使用了滑动窗口来保存采样数据。
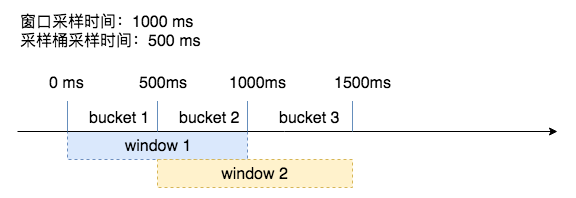
如上图,展示了一个具有两个桶(bucket)的滑动窗口(rolling window)。整个滑动窗口用来保存最近 1s 的采样数据,每个小的桶用来保存 500ms 的采样数据。 当时间流动之后,过期的桶会自动被新桶的数据覆盖掉,在图中,在 1000-1500ms 时,bucket 1 的数据因为过期而被丢弃,之后 bucket 3 的数据填到了窗口的头部。
限流公式
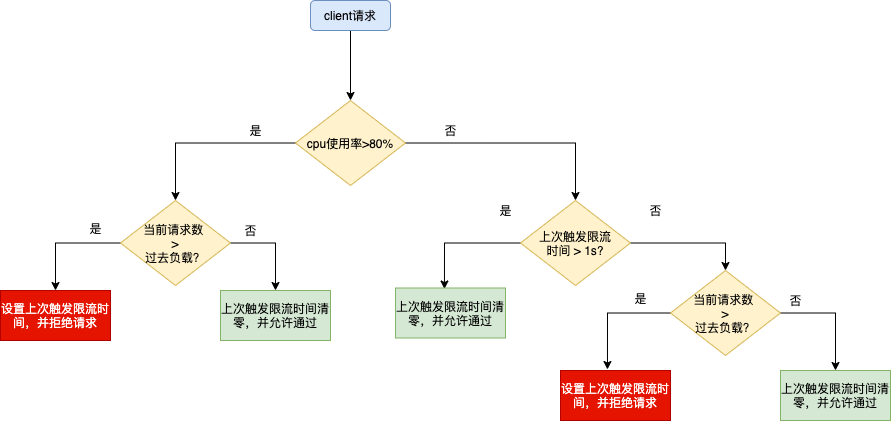
判断是否丢弃当前请求的算法如下:
cpu > 800 AND (Now - PrevDrop) < 1s AND (MaxPass * MinRt * windows / 1000) < InFlight
MaxPass 表示最近 5s 内,单个采样窗口中最大的请求数。 MinRt 表示最近 5s 内,单个采样窗口中最小的响应时间。 windows 表示一秒内采样窗口的数量,默认配置中是 5s 50 个采样,那么 windows 的值为 10。
源码分析
代码地址:
BBR struct
type BBR struct {
cpu cpuGetter
passStat window.RollingCounter
rtStat window.RollingCounter
inFlight int64
bucketPerSecond int64
bucketSize time.Duration
// prevDropTime defines previous start drop since initTime
prevDropTime atomic.Value
maxPASSCache atomic.Value
minRtCache atomic.Value
opts *options
}
cpu- cpu的指标函数,CPU的使用率, 这里为了减小误差,把数字扩大化,乘以1000,比赛使用率60%,也就是0.6 cpu的值就为600
passStat- 请求数的采样数据,使用滑动窗口进行统计
rtStat- 响应时间的采样数据,同样使用滑动窗口进行统计
inFlight- 当前系统中的请求数,数据得来方法是:中间件原理在处理前+1,处理handle之后不管成功失败都减去1
bucketPerSecond- 一个 bucket 的时间
bucketSize- 桶的数量
prevDropTime- 上次触发限流时间
maxPASSCache- 单个采样窗口中最大的请求数的缓存数据
minRtCache- 单个采样窗口中最小的响应时间的缓存数据
Allow接口
// Allow checks all inbound traffic.
// Once overload is detected, it raises limit.ErrLimitExceed error.
func (l *BBR) Allow(ctx context.Context) (func(), error) {
if l.shouldDrop() { // shouldDrop 判断是否需要限流,如果true表示拒绝 之后重点讲
return nil, ErrLimitExceed
}
atomic.AddInt64(&l.inFlight, 1) // 之前说的,正在处理数+1
stime := time.Since(initTime) // 现在时间减去程序初始化时间 表示程序开始执行时刻
return func() { // allow返回函数 在中间件(拦截器)中handle执行完成后调用
rt := int64((time.Since(initTime) - stime) / time.Millisecond) // 执行完handle的时间减去stime 表示 程序执行的总时间 单位ms
l.rtStat.Add(rt) // 把处理时间放进采样数据window
atomic.AddInt64(&l.inFlight, -1) // 正在处理数-1 便是处理完成
l.passStat.Add(1) // 成功了,把通过数的采样数据window加1
}, nil
}
shouldDrop方法
func (l *BBR) shouldDrop() bool {
curTime := time.Since(initTime)
if l.cpu() < l.opts.CPUThreshold {
// current cpu payload below the threshold
prevDropTime, _ := l.prevDropTime.Load().(time.Duration)
if prevDropTime == 0 {
// haven't start drop,
// accept current request
return false
}
if curTime-prevDropTime <= time.Second {
// just start drop one second ago,
// check current inflight count
inFlight := atomic.LoadInt64(&l.inFlight)
return inFlight > 1 && inFlight > l.maxInFlight()
}
l.prevDropTime.Store(time.Duration(0))
return false
}
// current cpu payload exceeds the threshold
inFlight := atomic.LoadInt64(&l.inFlight)
drop := inFlight > 1 && inFlight > l.maxInFlight()
if drop {
prevDrop, _ := l.prevDropTime.Load().(time.Duration)
if prevDrop != 0 {
// already started drop, return directly
return drop
}
// store start drop time
l.prevDropTime.Store(curTime)
}
return drop
}
maxInFlight()方法代表过去的负载
int64(math.Floor(float64(l.maxPASS()*l.minRT()*l.bucketPerSecond)/1000.0) + 0.5)
参考算法:https://github.com/alibaba/Sentinel/wiki/%E7%B3%BB%E7%BB%9F%E8%87%AA%E9%80%82%E5%BA%94%E9%99%90%E6%B5%81
- maxPass * bucketPerSecond / 1000 为每毫秒处理的请求数
- l.minRT() 为 单个采样窗口中最小的响应时间
- T ≈ QPS * Avg(RT)
+ 0.5为向上取整
流程图
压测报告
场景1,请求以每秒增加1个的速度不停上升,压测效果如下:
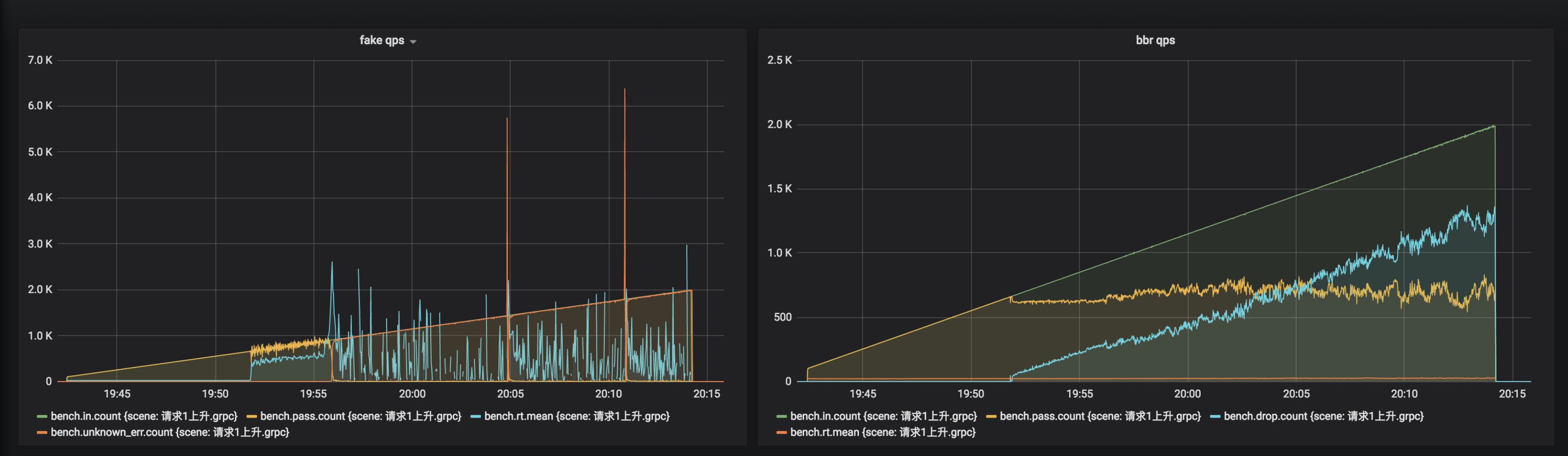
左测是没有限流的压测效果,右侧是带限流的压测效果。 可以看到,没有限流的场景里,系统在 700qps 时开始抖动,在 1k qps 时被拖垮,几乎没有新的请求能被放行,然而在使用限流之后,系统请求能够稳定在 600 qps 左右,rt 没有暴增,服务也没有被打垮,可见,限流有效的保护了服务。
原文地址:
参考文章:
- https://v1.go-kratos.dev/#/ratelimit
- https://github.com/alibaba/Sentinel/wiki/%E7%B3%BB%E7%BB%9F%E8%87%AA%E9%80%82%E5%BA%94%E9%99%90%E6%B5%81

