golang并发
goroutine
goroutine是Go并行设计的核心。goroutine说到底其实就是线程,但是它比线程更小,十几个goroutine可能体现在底层就是五六个线程,Go语言内部帮你实现了这些goroutine之间的内存共享。执行goroutine只需极少的栈内存(大概是4~5KB),当然会根据相应的数据伸缩。也正因为如此,可同时运行成千上万个并发任务。goroutine比thread更易用、更高效、更轻便。
goroutine是通过Go的runtime管理的一个线程管理器。goroutine通过go关键字实现了,其实就是一个普通的函数。
go hello(a, b, c)
通过关键字go就启动了一个goroutine。我们来看一个例子
package main
import (
"fmt"
"runtime"
)
func say(s string) {
for i := 0; i < 5; i++ {
runtime.Gosched()
fmt.Println(s)
}
}
func main() {
go say("world") //开一个新的Goroutines执行
say("hello") //当前Goroutines执行
}
// 以上程序执行后将输出:
// hello
// world
// hello
// world
// hello
// world
// hello
// world
// hello
我们可以看到go关键字很方便的就实现了并发编程。 上面的多个goroutine运行在同一个进程里面,共享内存数据,不过设计上我们要遵循:不要通过共享来通信,而要通过通信来共享。
goroutine的调度机制
Go runtime的调度器: 在了解Go的运行时的scheduler之前,需要先了解为什么需要它,因为我们可能会想,OS内核不是已经有一个线程scheduler了嘛? 熟悉POSIX API的人都知道,POSIX的方案在很大程度上是对Unix process进场模型的一个逻辑描述和扩展,两者有很多相似的地方。 Thread有自己的信号掩码,CPU affinity等。但是很多特征对于Go程序来说都是累赘。 尤其是context上下文切换的耗时。另一个原因是Go的垃圾回收需要所有的goroutine停止,使得内存在一个一致的状态。垃圾回收的时间点是不确定的,如果依靠OS自身的scheduler来调度,那么会有大量的线程需要停止工作。
单独的开发一个GO得调度器,可以是其知道在什么时候内存状态是一致的,也就是说,当开始垃圾回收时,运行时只需要为当时正在CPU核上运行的那个线程等待即可,而不是等待所有的线程。
用户空间线程和内核空间线程之间的映射关系有:N:1,1:1和M:N N:1是说,多个(N)用户线程始终在一个内核线程上跑,context上下文切换确实很快,但是无法真正的利用多核。 1:1是说,一个用户线程就只在一个内核线程上跑,这时可以利用多核,但是上下文switch很慢。 M:N是说, 多个goroutine在多个内核线程上跑,这个看似可以集齐上面两者的优势,但是无疑增加了调度的难度。
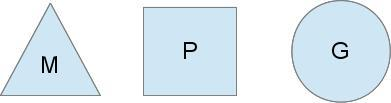
Go的调度器内部有三个重要的结构:M,P,S M:代表真正的内核OS线程,和POSIX里的thread差不多,真正干活的人 G:代表一个goroutine,它有自己的栈,instruction pointer和其他信息(正在等待的channel等等),用于调度。 P:代表调度的上下文,可以把它看做一个局部的调度器,使go代码在一个线程上跑,它是实现从N:1到N:M映射的关键。
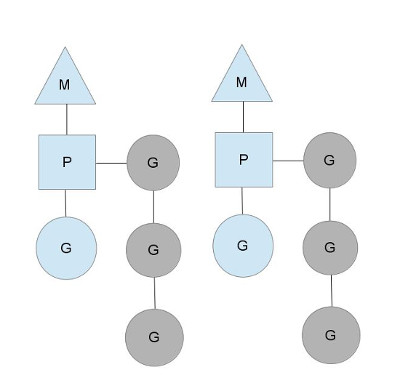
图中看,有2个物理线程M,每一个M都拥有一个context(P),每一个也都有一个正在运行的goroutine。 P的数量可以通过GOMAXPROCS()来设置,它其实也就代表了真正的并发度,即有多少个goroutine可以同时运行。 图中灰色的那些goroutine并没有运行,而是出于ready的就绪态,正在等待被调度。P维护着这个队列(称之为runqueue), Go语言里,启动一个goroutine很容易:go function 就行,所以每有一个go语句被执行,runqueue队列就在其末尾加入一个 goroutine,在下一个调度点,就从runqueue中取出(如何决定取哪个goroutine?)一个goroutine执行。
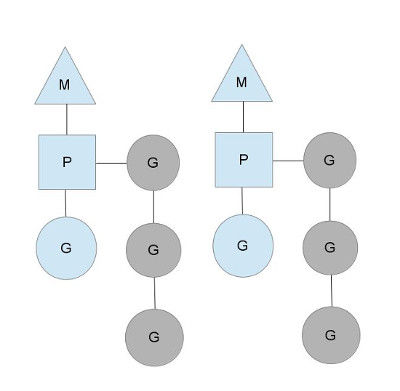
为何要维护多个上下文P?因为当一个OS线程被阻塞时,P可以转而投奔另一个OS线程! 图中看到,当一个OS线程M0陷入阻塞时,P转而在OS线程M1上运行。调度器保证有足够的线程来运行所以的context P。
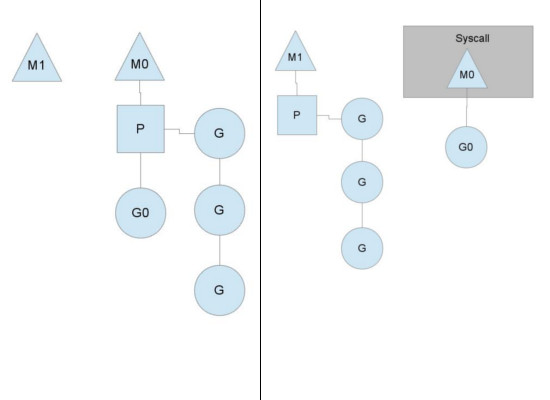
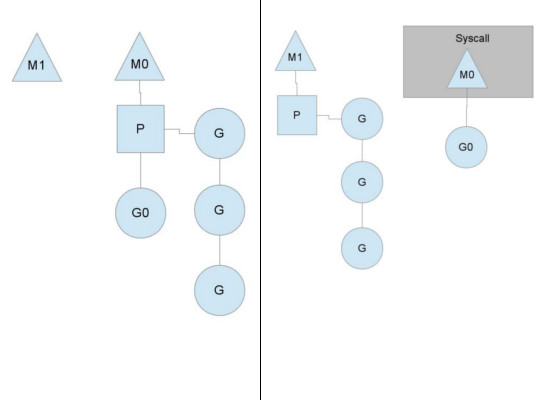
图中的M1可能是被创建,或者从线程缓存中取出。
当MO返回时,它必须尝试取得一个context P来运行goroutine,一般情况下,它会从其他的OS线程那里steal偷一个context过来, 如果没有偷到的话,它就把goroutine放在一个global runqueue里,然后自己就去睡大觉了(放入线程缓存里)。Contexts们也会周期性的检查global runqueue,否则global runqueue上的goroutine永远无法执行。
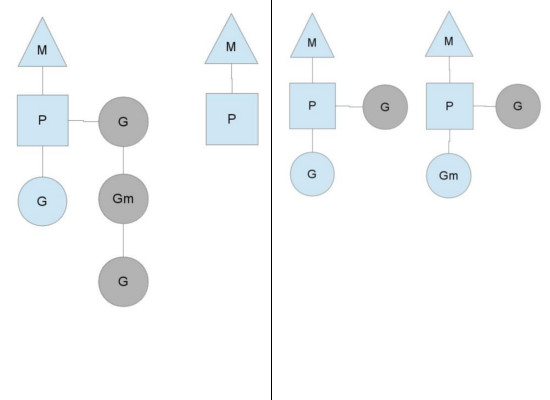
另一种情况是P所分配的任务G很快就执行完了(分配不均),这就导致了一个上下文P闲着没事儿干而系统却任然忙碌。但是如果global runqueue没有任务G了,那么P就不得不从其他的上下文P那里拿一些G来执行。一般来说,如果上下文P从其他的上下文P那里要偷一个任务的话,一般就‘偷’run queue的一半,这就确保了每个OS线程都能充分的使用。
channels
goroutine运行在相同的地址空间,因此访问共享内存必须做好同步。那么goroutine之间如何进行数据的通信呢,Go提供了一个很好的通信机制channel。channel可以与Unix shell 中的双向管道做类比:可以通过它发送或者接收值。这些值只能是特定的类型:channel类型。定义一个channel时,也需要定义发送到channel的值的类型。注意,必须使用make 创建channel:
ci := make(chan int)
cs := make(chan string)
cf := make(chan interface{})
channel通过操作符<-来接收和发送数据
ch <- v // 发送v到channel ch.
v := <-ch // 从ch中接收数据,并赋值给v
我们把这些应用到我们的例子中来:
package main
import "fmt"
func sum(a []int, c chan int) {
total := 0
for _, v := range a {
total += v
}
c <- total // send total to c
}
func main() {
a := []int{7, 2, 8, -9, 4, 0}
c := make(chan int)
go sum(a[:len(a)/2], c)
go sum(a[len(a)/2:], c)
x, y := <-c, <-c // receive from c
fmt.Println(x, y, x + y)
}
默认情况下,channel接收和发送数据都是阻塞的,除非另一端已经准备好,这样就使得Goroutines同步变的更加的简单,而不需要显式的lock。所谓阻塞,也就是如果读取(value := <-ch)它将会被阻塞,直到有数据接收。其次,任何发送(ch<-5)将会被阻塞,直到数据被读出。无缓冲channel是在多个goroutine之间同步很棒的工具。
Buffered Channels
上面我们介绍了默认的非缓存类型的channel,不过Go也允许指定channel的缓冲大小,很简单,就是channel可以存储多少元素。ch:= make(chan bool, 4),创建了可以存储4个元素的bool 型channel。在这个channel 中,前4个元素可以无阻塞的写入。当写入第5个元素时,代码将会阻塞,直到其他goroutine从channel 中读取一些元素,腾出空间。
ch := make(chan type, value)
/*
value == 0 ! 无缓冲(阻塞)
value > 0 ! 缓冲(非阻塞,直到value 个元素)
*/
我们看一下下面这个例子,你可以在自己本机测试一下,修改相应的value值
package main
import "fmt"
func main() {
c := make(chan int, 2)//修改2为1就报错,修改2为3可以正常运行
c <- 1
c <- 2
fmt.Println(<-c)
fmt.Println(<-c)
}
//修改为1报如下的错误:
//fatal error: all goroutines are asleep - deadlock!
Range和Close
上面这个例子中,我们需要读取两次c,这样不是很方便,Go考虑到了这一点,所以也可以通过range,像操作slice或者map一样操作缓存类型的channel,请看下面的例子
package main
import (
"fmt"
)
func fibonacci(n int, c chan int) {
x, y := 1, 1
for i := 0; i < n; i++ {
c <- x
x, y = y, x + y
}
close(c)
}
func main() {
c := make(chan int, 10)
go fibonacci(cap(c), c)
for i := range c {
fmt.Println(i)
}
}
for i := range c能够不断的读取channel里面的数据,直到该channel被显式的关闭。上面代码我们看到可以显式的关闭channel,生产者通过内置函数close关闭channel。关闭channel之后就无法再发送任何数据了,在消费方可以通过语法v, ok := <-ch测试channel是否被关闭。如果ok返回false,那么说明channel已经没有任何数据并且已经被关闭。
记住应该在生产者的地方关闭channel,而不是消费的地方去关闭它,这样容易引起panic
另外记住一点的就是channel不像文件之类的,不需要经常去关闭,只有当你确实没有任何发送数据了,或者你想显式的结束range循环之类的
Select
我们上面介绍的都是只有一个channel的情况,那么如果存在多个channel的时候,我们该如何操作呢,Go里面提供了一个关键字select,通过select可以监听channel上的数据流动。
select默认是阻塞的,只有当监听的channel中有发送或接收可以进行时才会运行,当多个channel都准备好的时候,select是随机的选择一个执行的。
package main
import "fmt"
func fibonacci(c, quit chan int) {
x, y := 1, 1
for {
select {
case c <- x:
x, y = y, x + y
case <-quit:
fmt.Println("quit")
return
}
}
}
func main() {
c := make(chan int)
quit := make(chan int)
go func() {
for i := 0; i < 10; i++ {
fmt.Println(<-c)
}
quit <- 0
}()
fibonacci(c, quit)
}
在select里面还有default语法,select其实就是类似switch的功能,default就是当监听的channel都没有准备好的时候,默认执行的(select不再阻塞等待channel)。
select {
case i := <-c:
// use i
default:
// 当c阻塞的时候执行这里
}
超时
有时候会出现goroutine阻塞的情况,那么我们如何避免整个程序进入阻塞的情况呢?我们可以利用select来设置超时,通过如下的方式实现:
func main() {
c := make(chan int)
o := make(chan bool)
go func() {
for {
select {
case v := <- c:
println(v)
case <- time.After(5 * time.Second):
println("timeout")
o <- true
break
}
}
}()
<- o
}
runtime goroutine
runtime包中有几个处理goroutine的函数:
Goexit
退出当前执行的goroutine,但是defer函数还会继续调用
Gosched
让出当前goroutine的执行权限,调度器安排其他等待的任务运行,并在下次某个时候从该位置恢复执行。
NumCPU
返回 CPU 核数量
NumGoroutine
返回正在执行和排队的任务总数
GOMAXPROCS
用来设置可以并行计算的CPU核数的最大值,并返回之前的值。
参考文章: