go 内存管理
操作系统内存管理
操作系统管理内存的存储单元是页(page),在 linux 中一般是 4KB。而且,操作系统还会使用 虚拟内存 来管理内存,在用户程序中,我们看到的内存是不是真实的内存,而是虚拟内存。当访问或者修改内存的时候,操作系统会将虚拟内存映射到真实的内存中。申请内存的组件是 Page Table 和 MMU(Memory Management Unit)。因为这个性能很重要,所以在 CPU 中专门有一个 TLB(Translation Lookaside Buffer)来缓存 Page Table 的内容。
为什么要用虚拟内存?
- 保护内存,每个进程都有自己的虚拟内存,不会相互干扰。防止修改和访问别的进程的内存。
- 减少内存碎片,虚拟内存是连续的,而真实的内存是不连续的。
- 当内存不够时,可以把虚拟内存映射到硬盘上,这样就可以使用硬盘的空间来扩展内存。
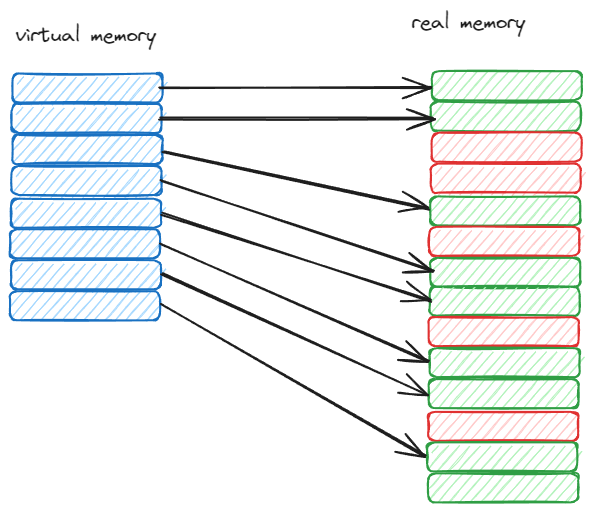
如上图所示,如果直接使用真实的内存,想要连续的内存肯定是申请不到的,这就是内存碎片的问题。而使用虚拟内存,通过 Page 映射的方式,保证内存连续。
Go 内存管理单元
page
在 go 中,管理内存的存储单元也是页(Page), 每个页的大小是 8KB。Go 内存管理是由 runtime 来管理的,runtime 会维护一个内存池,用来分配和回收内存。这样可以避免频繁的系统调用申请内存,提高性能。
mspan
mspan 是 go 内存管理基本单元,一个 mspan 包含一个或者多个 page。go 中有多种 mspan,每种 mspan 给不同的内存大小使用。
| class | bytes/obj | bytes/span | objects | tail waste | max waste | min align |
|---|---|---|---|---|---|---|
| 1 | 8 | 8192 | 1024 | 0 | 87.50% | 8 |
| 2 | 16 | 8192 | 512 | 0 | 43.75% | 16 |
| 3 | 24 | 8192 | 341 | 8 | 29.24% | 8 |
| 4 | 32 | 8192 | 256 | 0 | 21.88% | 32 |
| 5 | 48 | 8192 | 170 | 32 | 31.52% | 16 |
| 6 | 64 | 8192 | 128 | 0 | 23.44% | 64 |
| 7 | 80 | 8192 | 102 | 32 | 19.07% | 16 |
| 8 | 96 | 8192 | 85 | 32 | 15.95% | 32 |
| 9 | 112 | 8192 | 73 | 16 | 13.56% | 16 |
| … | … | … | … | … | … | … |
| 64 | 24576 | 24576 | 1 | 0 | 11.45% | 8192 |
| 65 | 27264 | 81920 | 3 | 128 | 10.00% | 128 |
| 66 | 28672 | 57344 | 2 | 0 | 4.91% | 4096 |
| 67 | 32768 | 32768 | 1 | 0 | 12.50% | 8192 |
- class 是 mspan 的类型,每种类型对应不同的内存大小。
- obj 是每个对象的大小。
- span 是 mspan 的大小。
- objects 是 mspan 中对象的个数。
- tail waste 是 mspan 中最后一个对象的浪费空间。(不能整除造成的)
- max waste 是 mspan 中最大的浪费空间。(比如第一个中 每个都使用 1 byte,那么就所有都浪费 7 byte,7 / 8 = 87.50%)
- min align 是 mspan 中对象的对齐大小。如果超过这个就会分配下一个 mspan。
数据结构
mspan
type mspan struct {
// 双向链表 下一个 mspan 和 上一个 mspan
next *mspan
prev *mspan
// debug 使用的
list *mSpanList
// 起始地址和页数 当 class 太大 要多个页组成 mspan
startAddr uintptr
npages uintptr
// 手动管理的空闲对象链表
manualFreeList gclinkptr
// 下一个空闲对象的地址 如果小于它 就不用检索了 直接从这个地址开始 提高效率
freeindex uint16
// 对象的个数
nelems uint16
// GC 扫描使用的空闲索引
freeIndexForScan uint16
// bitmap 每个 bit 对应一个对象 标记是否使用
allocCache uint64
// ...
// span 的类型
spanclass spanClass // size class and noscan (uint8)
// ...
}
spanClass
type spanClass uint8
func makeSpanClass(sizeclass uint8, noscan bool) spanClass {
return spanClass(sizeclass<<1) | spanClass(bool2int(noscan))
}
//go:nosplit
func (sc spanClass) sizeclass() int8 {
return int8(sc >> 1)
}
//go:nosplit
func (sc spanClass) noscan() bool {
return sc&1 != 0
}
spanClass 是 unint8 类型,一共有 8 位,前 7 位是 sizeclass,也就是上边 table 中的内容,一共有 (67 + 1) * 2 种类型, +1 是 0 代表比 67 class 的内存还大。最后一位是 noscan,也就是表示这个对象中是否含有指针,用来给 GC 扫描加速用的(无指针对象就不用继续扫描了),所以要 * 2。
mspan 详解
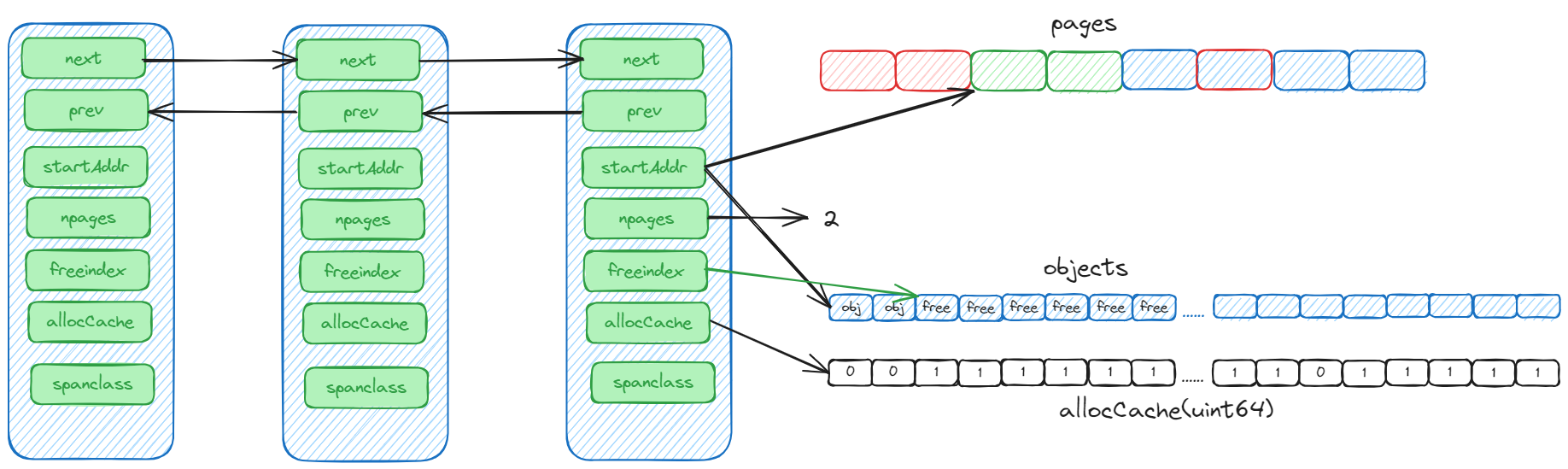
如果所示
- mspan 是一个双向链表,如果不够用了,在挂一个就行了。
- startAddr 是 mspan 的起始地址,npages 是 page 数量。根据 startAddr + npages * 8KB 就可以得到 mspan 的结束地址。
- allocCache 是一个 bitmap,每个 bit 对应一个对象,标记是否使用。使用了 ctz(count trailing zero)。
- freeindex 是下一个空闲对象的地址,如果小于它,就不用检索了,直接从这个地址开始,提高效率。
mcache
mache 是每个 P (processor)的结构体中都有的,是用来缓存的,因为每个 P 同一时间只有一个 goroutine 在执行,所以 mcache 是不需要加锁的。这也是 mcache 的设计初衷,减少锁的竞争,提高性能。
type p struct {
// ...
mcache *mcache
// ...
}
// 每个 P 的本队缓存
type mcache struct {
// 不在 gc 的堆中分配
_ sys.NotInHeap
// The following members are accessed on every malloc,
// so they are grouped here for better caching.
nextSample uintptr // trigger heap sample after allocating this many bytes
scanAlloc uintptr // bytes of scannable heap allocated
// 微对象分配器(<16B 不含指针)
tiny uintptr // 内存的其实地址
tinyoffset uintptr // 偏移量
tinyAllocs uintptr // 分配了多少个 tiny 对象
// span缓存数组,按大小类别索引
alloc [numSpanClasses]*mspan // spans to allocate from, indexed by spanClass
// 用于不同大小的栈内存分配 go 的 堆上分配栈内存
stackcache [_NumStackOrders]stackfreelist
// 控制 mcache 的刷新
flushGen atomic.Uint32
}
mcentral
mcentral 也是一种缓存,只不过在中心而不是在每个 P 上。mcentral 存在的意义也是减少锁竞争,如果没有 mcentral,那么只要从中心申请 mspan 就需要加锁。现在加上了 mcentral,申请时就需要加特别力度的锁就可以了,比如申请 class = 1 的 mspan 加 class = 1 的锁就可以了,不影响别人申请 class = 2 的 mspan。这样就可以较少锁竞争,提高性能。
type mcentral struct {
_ sys.NotInHeap
// mspan 的类别
spanclass spanClass
// 部分使用的span列表
// 使用两个集合交替角色
// [0] -> 已清扫的spans
// [1] -> 未清扫的spans
partial [2]spanSet // list of spans with a free object
// 完全使用的 mspan
full [2]spanSet // list of spans with no free objects
}
type spanSet struct {
// spanSet是一个两级数据结构,由一个可增长的主干(spine)指向固定大小的块组成。
// 访问spine不需要锁,但添加块或扩展spine时需要获取spine锁。
//
// 因为每个mspan至少覆盖8K的堆内存,且在spanSet中最多占用8字节,
// 所以spine的增长是相当有限的。
// 锁
spineLock mutex
// 原子指针,指向一个动态数组
spine atomicSpanSetSpinePointer // *[N]atomic.Pointer[spanSetBlock]
// 当前spine数组中实际使用的长度 原子类型
spineLen atomic.Uintptr // Spine array length
// spine数组的容量
spineCap uintptr // Spine array cap, accessed under spineLock
// index是spanSet中的头尾指针,被压缩在一个字段中。
// head和tail都表示所有块的逻辑连接中的索引位置,其中head总是在tail之后或等于tail
// (等于tail时表示集合为空)。这个字段始终通过原子操作访问。
//
// head和tail各自的宽度为32位,这意味着在需要重置之前,我们最多支持2^32次push操作。
// 如果堆中的每个span都存储在这个集合中,且每个span都是最小尺寸(1个运行时页面,8 KiB),
// 那么大约需要32 TiB大小的堆才会导致无法表示的情况。
// 头部索引
index atomicHeadTailIndex
}
type mheap struct {
central [numSpanClasses]struct {
mcentral mcentral
// 填充字节 一般不能整除的时候 末尾的余数就不用了
pad [(cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize) % cpu.CacheLinePadSize]byte
}
}
mheap
mheap 是全局的内存管理器,申请内存是 mcentral 不满足要求的时候,就会从 mheap 中申请,要加全局锁。如果 mheap 还不能满足,就会系统调用从操作系统申请,每次申请的最小单位是 Arena,也就是 64M。
type mheap struct {
_ sys.NotInHeap
// 全局锁
lock mutex
// page 分配器 管理所有的page
pages pageAlloc
sweepgen uint32 // sweep 代数 gc时候使用
// 所有的 mspan
allspans []*mspan
// 正在使用的 page 数
pagesInUse atomic.Uintptr
// ......
// 用于定位内存地址是哪个 mspan 的
// 二维数组 1 << arenaL1Bits = 1 1 << arenaL2Bits = 4194304
arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena
spanalloc fixalloc // span 分配器
cachealloc fixalloc // mcache 分配器
specialfinalizeralloc fixalloc // finalizer 分配器
// ......
}
heapArena
// A heapArena stores metadata for a heap arena. heapArenas are stored
// outside of the Go heap and accessed via the mheap_.arenas index.
type heapArena struct {
_ sys.NotInHeap
// page 对应的 mspan
// pagesPerArena 8192 一个 page 8KB 所以一个 heapArena 可以存储 64M 的内存
spans [pagesPerArena]*mspan
// 标记哪个 page 是在使用的
// /8 是 uint8 可以表示 8 个 page
pageInUse [pagesPerArena / 8]uint8
// 标记哪些span包含被标记的对象 用于 gc 加速
pageMarks [pagesPerArena / 8]uint8
// 标记哪些span包含特殊对象
pageSpecials [pagesPerArena / 8]uint8
checkmarks *checkmarksMap
// arena中第一个未使用(已归零)页面的起始字节
zeroedBase uintptr
}
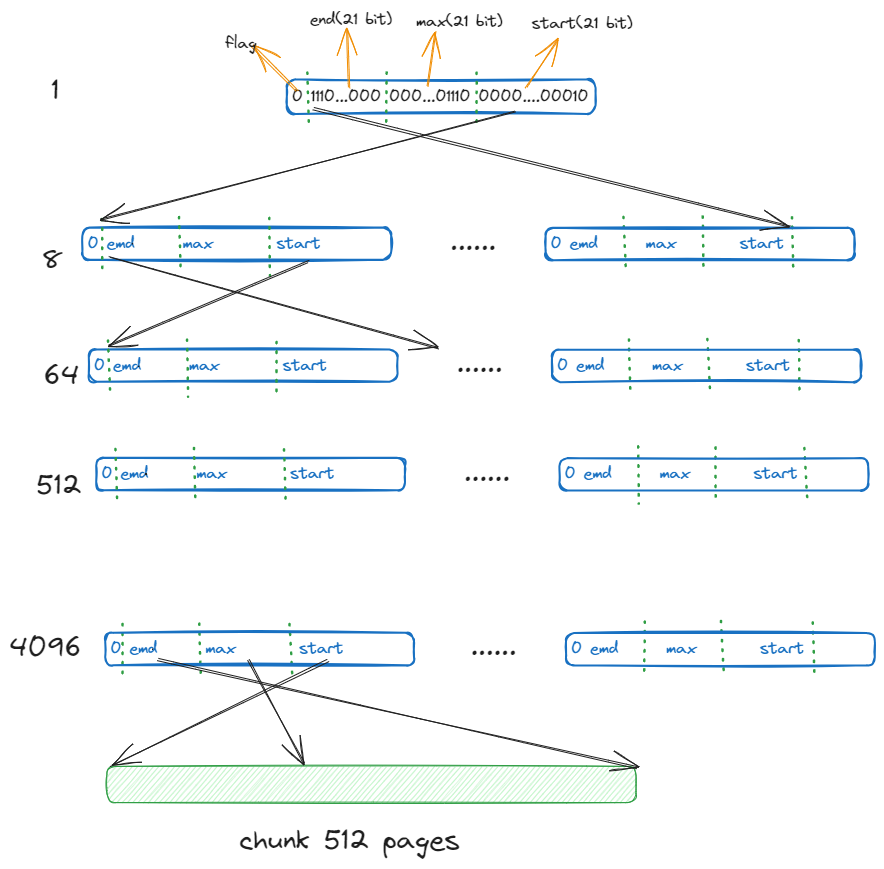
pageAlloc
分配 page 的结构体,是一个 radix tree 的结构,一共有 5 层,每一层都是一个 summary 数组,用于快速查找空闲页面。
type pageAlloc struct {
// 基数树 一共有 summaryLevels=5 层
// 基数树的摘要数组,用于快速查找空闲页面
summary [summaryLevels][]pallocSum
// 二级页面位图结构
// 使用二级结构而不是一个大的扁平数组,是因为在64位平台上总大小可能非常大(O(GiB))
chunks [1 << pallocChunksL1Bits]*[1 << pallocChunksL2Bits]pallocData
// 搜索起始地址
searchAddr offAddr
// start 和 end 表示 pageAlloc 知道的块索引范围
start, end chunkIdx
// ......
}
type pallocSum uint64
// pallocSum 被划分成几个部分:
// 63位 62-42位 41-21位 20-0位
// [标志位] [end值] [max值] [start值]
// 1 21位 21位 21位
func (p pallocSum) start() uint {
// 检查第63位是否为1
if uint64(p)&uint64(1<<63) != 0 {
return maxPackedValue
}
// 否则,取最低21位
return uint(uint64(p) & (maxPackedValue - 1))
}
func (p pallocSum) max() uint {
if uint64(p)&uint64(1<<63) != 0 {
return maxPackedValue
}
// 右移21位,然后取21位
return uint((uint64(p) >> logMaxPackedValue) & (maxPackedValue - 1))
}
func (p pallocSum) end() uint {
if uint64(p)&uint64(1<<63) != 0 {
return maxPackedValue
}
// 右移42位,然后取21位
return uint((uint64(p) >> (2 * logMaxPackedValue)) & (maxPackedValue - 1))
}
内存分配流程
流程
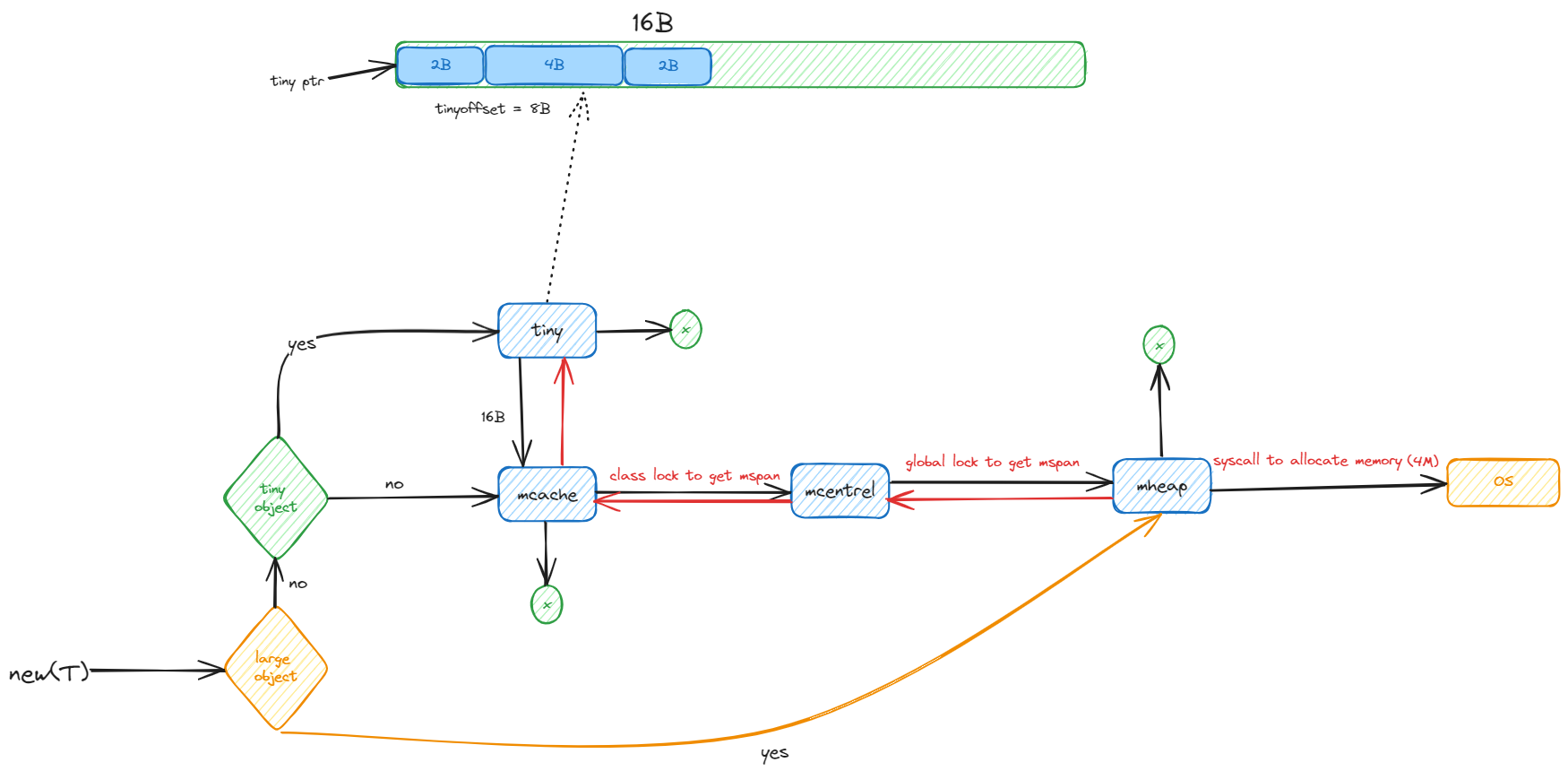
go 中把 对象分成三类 tiny ,small 和 large。tiny 是小于 16B 的对象,small 是大于等于 16B 小于 32KB 的对象,large 是大于 32KB 的对象。tiny 分配器主要是为了减少内存碎片。
- 如果是 tiny object,直接使用 tiny 分配器分配。如果 tiny 分配器中的空间不够(定长位16B),就从 mchunk 中获取一个新的 16B 的对象作为 tiny 分配器的空间使用。
- 如果是 small object,根据所属的 class, 从 mcache 获取对应 mspan 中的内存。
- 如果 mspan 中的内存不够,根据所属的 class 从 mcentral 中获取新的 mspan ,从 mspan 中获取内存。(要 class 力度的锁)
- 如果 mcentral 中的 mspan 也不够,就从 mheap 中获取对应数量的 page 组装成 mspan,然后从新的 mspan 中获取内存。(全局锁)
- 如果 mheap 中的 mspan 也不够,就系统调用从操作系统获取新的 Arena。把内存 page 分配好,然后继续第四步。
- 如果是 large object,直接从第四部开始。
mallocgc
// 在 heap 上分配内存函数 size 对象大小 typ 对象类型 needzero 是否需要清零
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
// gc 终止阶段不允许分配 这个是一个检查 正常情况下不会出现
if gcphase == _GCmarktermination {
throw("mallocgc called with gcphase == _GCmarktermination")
}
// 处理分类为 0 的情况
if size == 0 {
return unsafe.Pointer(&zerobase)
}
// ......
// Set mp.mallocing to keep from being preempted by GC.
mp := acquirem()
if mp.mallocing != 0 {
throw("malloc deadlock")
}
if mp.gsignal == getg() {
throw("malloc during signal")
}
mp.mallocing = 1
shouldhelpgc := false
dataSize := userSize
// 获取 M 和 M 所属 P 的 mcache
c := getMCache(mp)
if c == nil {
throw("mallocgc called without a P or outside bootstrapping")
}
var span *mspan
var header **_type
var x unsafe.Pointer
// 对象总是不是含有指针 如果不含有 就不用往下扫描了 用来 gc 加速
noscan := typ == nil || !typ.Pointers()
// 是不是小对象 (< 32k - 8)
if size <= maxSmallSize-mallocHeaderSize {
// 如果对象大小小于 16B 且不含有指针 则使用 tiny 分配器
if noscan && size < maxTinySize {
off := c.tinyoffset
// 内存对齐一下
if size&7 == 0 {
off = alignUp(off, 8)
} else if goarch.PtrSize == 4 && size == 12 {
off = alignUp(off, 8)
} else if size&3 == 0 {
off = alignUp(off, 4)
} else if size&1 == 0 {
off = alignUp(off, 2)
}
// 如果剩余空间足够 使用 tiny 分配器
if off+size <= maxTinySize && c.tiny != 0 {
x = unsafe.Pointer(c.tiny + off)
c.tinyoffset = off + size
c.tinyAllocs++
mp.mallocing = 0
releasem(mp)
return x
}
// 重新 分配一个 tiny 使用
span = c.alloc[tinySpanClass]
v := nextFreeFast(span)
if v == 0 {
v, span, shouldhelpgc = c.nextFree(tinySpanClass)
}
x = unsafe.Pointer(v)
(*[2]uint64)(x)[0] = 0
(*[2]uint64)(x)[1] = 0
if !raceenabled && (size < c.tinyoffset || c.tiny == 0) {
c.tiny = uintptr(x)
c.tinyoffset = size
}
size = maxTinySize
} else {
// 处理小对象
// 处理对象头部 主要加入一些头部信息帮助 GC 加速
hasHeader := !noscan && !heapBitsInSpan(size)
if hasHeader {
size += mallocHeaderSize
}
// 根据不同的对象大小 使用不同的mspan
var sizeclass uint8
if size <= smallSizeMax-8 {
sizeclass = size_to_class8[divRoundUp(size, smallSizeDiv)]
} else {
sizeclass = size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]
}
size = uintptr(class_to_size[sizeclass])
spc := makeSpanClass(sizeclass, noscan)
span = c.alloc[spc]
// 使用缓存从 mspan 中获取空闲对象
v := nextFreeFast(span)
if v == 0 {
// 先从本地获取 span 如果本地没获取到 升级到 mcenral 获取
v, span, shouldhelpgc = c.nextFree(spc)
}
x = unsafe.Pointer(v)
// 如果需要清零 处理一下
if needzero && span.needzero != 0 {
memclrNoHeapPointers(x, size)
}
// 设置头
if hasHeader {
header = (**_type)(x)
x = add(x, mallocHeaderSize)
size -= mallocHeaderSize
}
}
} else {
// 大对象分配 直接从 mheap 中获取 class = 0 的 mspan
shouldhelpgc = true
span = c.allocLarge(size, noscan)
span.freeindex = 1
span.allocCount = 1
size = span.elemsize
x = unsafe.Pointer(span.base())
if needzero && span.needzero != 0 {
delayedZeroing = true
}
if !noscan {
// Tell the GC not to look at this yet.
span.largeType = nil
header = &span.largeType
}
}
// ......
return x
}
nextFreeFast
func nextFreeFast(s *mspan) gclinkptr {
// 使用 ctz64 (amd64 中是 tzcnt 指令 ) 获取末尾的 0(以分配) 的个数 如果是 64 说明没有空闲对象
theBit := sys.TrailingZeros64(s.allocCache)
// 如果找到了空闲位置(theBit < 64)
if theBit < 64 {
result := s.freeindex + uint16(theBit)
if result < s.nelems {
freeidx := result + 1
if freeidx%64 == 0 && freeidx != s.nelems {
return 0
}
// 分配了 cache 移动一下
s.allocCache >>= uint(theBit + 1)
s.freeindex = freeidx
s.allocCount++
// result * elemsize:计算对象的偏移量
// base():获取span的起始地址
return gclinkptr(uintptr(result)*s.elemsize + s.base())
}
}
return 0
}
nextFree
// nextFree 从 mcache 中获取下一个空闲对象
func (c *mcache) nextFree(spc spanClass) (v gclinkptr, s *mspan, shouldhelpgc bool) {
s = c.alloc[spc]
shouldhelpgc = false
// 从 mcache 对象空位的偏移量
freeIndex := s.nextFreeIndex()
if freeIndex == s.nelems {
// mcache 没有靠你先对象 从 mcentral,mheap 获取
c.refill(spc)
shouldhelpgc = true
s = c.alloc[spc]
freeIndex = s.nextFreeIndex()
}
if freeIndex >= s.nelems {
throw("freeIndex is not valid")
}
v = gclinkptr(uintptr(freeIndex)*s.elemsize + s.base())
s.allocCount++
if s.allocCount > s.nelems {
println("s.allocCount=", s.allocCount, "s.nelems=", s.nelems)
throw("s.allocCount > s.nelems")
}
return
}
一组一组获取空闲对象
func (s *mspan) nextFreeIndex() uint16 {
sfreeindex := s.freeindex
snelems := s.nelems
if sfreeindex == snelems {
return sfreeindex
}
if sfreeindex > snelems {
throw("s.freeindex > s.nelems")
}
aCache := s.allocCache
bitIndex := sys.TrailingZeros64(aCache)
for bitIndex == 64 {
// Move index to start of next cached bits.
sfreeindex = (sfreeindex + 64) &^ (64 - 1)
if sfreeindex >= snelems {
s.freeindex = snelems
return snelems
}
whichByte := sfreeindex / 8
// Refill s.allocCache with the next 64 alloc bits.
s.refillAllocCache(whichByte)
aCache = s.allocCache
bitIndex = sys.TrailingZeros64(aCache)
// nothing available in cached bits
// grab the next 8 bytes and try again.
}
result := sfreeindex + uint16(bitIndex)
if result >= snelems {
s.freeindex = snelems
return snelems
}
s.allocCache >>= uint(bitIndex + 1)
sfreeindex = result + 1
if sfreeindex%64 == 0 && sfreeindex != snelems {
whichByte := sfreeindex / 8
s.refillAllocCache(whichByte)
}
s.freeindex = sfreeindex
return result
}
// 给 mcache 添加一个新的 mspan 一般是申请内存 mcache 中没有空闲对象了
func (c *mcache) refill(spc spanClass) {
s := c.alloc[spc]
if s.allocCount != s.nelems {
throw("refill of span with free space remaining")
}
if s != &emptymspan {
// ......
// 如果不是空的 而且没有空闲对象 就把这个 span 放到 mcentral 中 mcache 使用不了这个 span 了
mheap_.central[spc].mcentral.uncacheSpan(s)
// ......
}
// 从 mcentral 获取新的 span 如果没有就从 mheap 再没有就系统调用申请内存
s = mheap_.central[spc].mcentral.cacheSpan()
// .....
c.alloc[spc] = s
}
cacheSpan
func (c *mcentral) cacheSpan() *mspan {
// ......
// 尝试从以清扫的部分获取
sg := mheap_.sweepgen
if s = c.partialSwept(sg).pop(); s != nil {
goto havespan
}
// 如果以清扫的没有 就马上开始主动清扫
sl = sweep.active.begin()
if sl.valid {
// 尝试从未清扫的部分使用的 span 列表中获取
for ; spanBudget >= 0; spanBudget-- {
s = c.partialUnswept(sg).pop()
if s == nil {
break
}
// 尝试获取 span
if s, ok := sl.tryAcquire(s); ok {
// 清扫它 并使用
s.sweep(true)
sweep.active.end(sl)
goto havespan
}
}
// 尝试从未清扫的已满 span 列表中获取
for ; spanBudget >= 0; spanBudget-- {
s = c.fullUnswept(sg).pop()
if s == nil {
break
}
if s, ok := sl.tryAcquire(s); ok {
s.sweep(true)
// 清扫之后 看有无可用的 没有就下一个
freeIndex := s.nextFreeIndex()
if freeIndex != s.nelems {
s.freeindex = freeIndex
sweep.active.end(sl)
goto havespan
}
c.fullSwept(sg).push(s.mspan)
}
}
sweep.active.end(sl)
}
trace = traceAcquire()
if trace.ok() {
trace.GCSweepDone()
traceDone = true
traceRelease(trace)
}
// mcentral 中没有可用的 span 了 从 mheap 中获取
s = c.grow()
if s == nil {
return nil
}
// 获取到了 span 了 上边会 goto 到这
havespan:
// ......
// 处理 allocCache 缓存
freeByteBase := s.freeindex &^ (64 - 1)
whichByte := freeByteBase / 8
s.refillAllocCache(whichByte)
s.allocCache >>= s.freeindex % 64
return s
}
grow
func (c *mcentral) grow() *mspan {
npages := uintptr(class_to_allocnpages[c.spanclass.sizeclass()])
size := uintptr(class_to_size[c.spanclass.sizeclass()])
// 申请内存
s := mheap_.alloc(npages, c.spanclass)
if s == nil {
return nil
}
// 计算这个 span 可以容纳多少个对象 和 偏移量等
n := s.divideByElemSize(npages << _PageShift)
s.limit = s.base() + size*n
s.initHeapBits(false)
return s
}
func (h *mheap) alloc(npages uintptr, spanclass spanClass) *mspan {
var s *mspan
systemstack(func() {
// 先清扫一些页 防止一直增长
if !isSweepDone() {
h.reclaim(npages)
}
s = h.allocSpan(npages, spanAllocHeap, spanclass)
})
return s
}
func (h *mheap) allocSpan(npages uintptr, typ spanAllocType, spanclass spanClass) (s *mspan) {
// 检查内存对其 ......
if !needPhysPageAlign && pp != nil && npages < pageCachePages/4 {
// 尝试从缓存直接获取
*c = h.pages.allocToCache()
}
// 加锁
lock(&h.lock)
if needPhysPageAlign {
// Overallocate by a physical page to allow for later alignment.
extraPages := physPageSize / pageSize
// 尝试从 pageAlloc 获取页
base, _ = h.pages.find(npages + extraPages)
}
if base == 0 {
// 尝试分配所需页数
base, scav = h.pages.alloc(npages)
if base == 0 {
var ok bool
// 空间不足,尝试扩展
growth, ok = h.grow(npages)
if !ok {
unlock(&h.lock)
return nil
}
base, scav = h.pages.alloc(npages)
if base == 0 {
throw("grew heap, but no adequate free space found")
}
}
}
unlock(&h.lock)
HaveSpan:
// ......
// 组装成 mspan
h.initSpan(s, typ, spanclass, base, npages)
return s
}
// 向操作系统申请内存
func (h *mheap) grow(npage uintptr) (uintptr, bool) {
// 每次申请 4 M
ask := alignUp(npage, pallocChunkPages) * pageSize
// ......
av, asize := h.sysAlloc(ask, &h.arenaHints, true)
// ......
}
// sysAlloc -> sysReserve -> sysReserveOS
func sysReserveOS(v unsafe.Pointer, n uintptr) unsafe.Pointer {
p, err := mmap(v, n, _PROT_NONE, _MAP_ANON|_MAP_PRIVATE, -1, 0)
if err != 0 {
return nil
}
return p
}
func mmap(addr unsafe.Pointer, n uintptr, prot, flags, fd int32, off uint32) (unsafe.Pointer, int) {
// ......
return sysMmap(addr, n, prot, flags, fd, off)
}
stack 内存
// newproc1
if newg == nil {
newg = malg(stackMin)
}
//newproc1 -> malg -> stackalloc
func stackalloc(n uint32) stack {
thisg := getg()
// ......
var v unsafe.Pointer
// 小栈 linux 下是 32k
if n < fixedStack<<_NumStackOrders && n < _StackCacheSize {
order := uint8(0)
n2 := n
for n2 > fixedStack {
order++
n2 >>= 1
}
var x gclinkptr
// 以下情况直接从全局池分配:
// 1. 禁用栈缓存
// 2. 没有关联的 P
// 3. 禁用抢占
if stackNoCache != 0 || thisg.m.p == 0 || thisg.m.preemptoff != "" {
lock(&stackpool[order].item.mu)
x = stackpoolalloc(order)
unlock(&stackpool[order].item.mu)
} else {
// 从 P 的本地缓存分配
c := thisg.m.p.ptr().mcache
x = c.stackcache[order].list
// 如果本地缓存为空,则重新填充
if x.ptr() == nil {
stackcacherefill(c, order)
x = c.stackcache[order].list
}
c.stackcache[order].list = x.ptr().next
c.stackcache[order].size -= uintptr(n)
}
v = unsafe.Pointer(x)
} else {
// 大栈
var s *mspan
npage := uintptr(n) >> _PageShift
log2npage := stacklog2(npage)
// Try to get a stack from the large stack cache.
lock(&stackLarge.lock)
if !stackLarge.free[log2npage].isEmpty() {
s = stackLarge.free[log2npage].first
stackLarge.free[log2npage].remove(s)
}
unlock(&stackLarge.lock)
lockWithRankMayAcquire(&mheap_.lock, lockRankMheap)
if s == nil {
// 从堆中分配新的栈空间
s = mheap_.allocManual(npage, spanAllocStack)
if s == nil {
throw("out of memory")
}
osStackAlloc(s)
s.elemsize = uintptr(n)
}
v = unsafe.Pointer(s.base())
}
// ...
return stack{uintptr(v), uintptr(v) + uintptr(n)}
}
stackpoolalloc stackpool
var stackpool [_NumStackOrders]struct {
item stackpoolItem
_ [(cpu.CacheLinePadSize - unsafe.Sizeof(stackpoolItem{})%cpu.CacheLinePadSize) % cpu.CacheLinePadSize]byte
}
type stackpoolItem struct {
_ sys.NotInHeap
mu mutex
span mSpanList
}
func stackpoolalloc(order uint8) gclinkptr {
list := &stackpool[order].item.span
s := list.first
if s == nil {
// 从 mheap 中申请 class = 0 对应页数的
s = mheap_.allocManual(_StackCacheSize>>_PageShift, spanAllocStack)
// ...
}
// 分配内存
x := s.manualFreeList
// ...
return x
}
stackcache
type mcache struct {
stackcache [_NumStackOrders]stackfreelist
}
type stackfreelist struct {
list gclinkptr
size uintptr
}
type gclinkptr uintptr
func (p gclinkptr) ptr() *gclink {
return (*gclink)(unsafe.Pointer(p))
}
stackcacherefill
func stackcacherefill(c *mcache, order uint8) {
for size < _StackCacheSize/2 {
x := stackpoolalloc(order)
x.ptr().next = list
list = x
size += fixedStack << order
}
unlock(&stackpool[order].item.mu)
c.stackcache[order].list = list
c.stackcache[order].size = size
}
回收
//Goexit -> goexit1 -> goexit0 -> gdestroy
func gdestroy(gp *g) {
// ......
// 修改状态
casgstatus(gp, _Grunning, _Gdead)
// 把 gp 的变量制空 .......
// 把 m 上的 g 制空
dropg()
gfput(pp, gp)
}
func gfput(pp *p, gp *g) {
// ......
stksize := gp.stack.hi - gp.stack.lo
// 如果栈不是默认大小 直接释放掉 只有默认大小才去复用
if stksize != uintptr(startingStackSize) {
// non-standard stack size - free it.
stackfree(gp.stack)
gp.stack.lo = 0
gp.stack.hi = 0
gp.stackguard0 = 0
}
// 将 goroutine 放入空闲队列
pp.gFree.push(gp)
pp.gFree.n++
// 如果到达 64 个 goroutine 就把一部分放到全局队列中
if pp.gFree.n >= 64 {
var (
inc int32
stackQ gQueue
noStackQ gQueue
)
for pp.gFree.n >= 32 {
gp := pp.gFree.pop()
pp.gFree.n--
if gp.stack.lo == 0 {
noStackQ.push(gp)
} else {
stackQ.push(gp)
}
inc++
}
lock(&sched.gFree.lock)
sched.gFree.noStack.pushAll(noStackQ)
sched.gFree.stack.pushAll(stackQ)
sched.gFree.n += inc
unlock(&sched.gFree.lock)
}
}
stackfree
func stackfree(stk stack) {
// ......
if n < fixedStack<<_NumStackOrders && n < _StackCacheSize {
// 小栈(< 32k) 留着复用一下
order := uint8(0)
n2 := n
for n2 > fixedStack {
order++
n2 >>= 1
}
x := gclinkptr(v)
// 如果不使用缓存或当前处理器被抢占,使用全局栈池
if stackNoCache != 0 || gp.m.p == 0 || gp.m.preemptoff != "" {
lock(&stackpool[order].item.mu)
stackpoolfree(x, order)
unlock(&stackpool[order].item.mu)
} else {
// 否则,使用本地缓存
c := gp.m.p.ptr().mcache
if c.stackcache[order].size >= _StackCacheSize {
stackcacherelease(c, order)
}
x.ptr().next = c.stackcache[order].list
c.stackcache[order].list = x
c.stackcache[order].size += n
}
} else {
// 如果栈大小不适合缓存,检查其 span 状态并相应处理
s := spanOfUnchecked(uintptr(v))
if s.state.get() != mSpanManual {
println(hex(s.base()), v)
throw("bad span state")
}
if gcphase == _GCoff {
// 如果 GC 未运行,立即释放栈
osStackFree(s)
mheap_.freeManual(s, spanAllocStack)
} else {
// 如果 GC 运行中,将栈添加到大栈缓存,避免与 GC 竞态
log2npage := stacklog2(s.npages)
lock(&stackLarge.lock)
stackLarge.free[log2npage].insert(s)
unlock(&stackLarge.lock)
}
}
}