Prometheus
Prometheus简介
什么是 Prometheus
Prometheus 是在 Soundcloud 以开源软件的形式进行研发的系统监控和告警工具包,自此以后,许多公司和组织都采用了 Prometheus 作为监控告警工具。Prometheus 的开发者和用户社区非常活跃,它现在是一个独立的开源项目,可以独立于任何公司进行维护。Prometheus 于 2016 年 5 月加入 CNCF 基金会,成为继 Kubernetes 之后的第二个 CNCF 托管项目。
Prometheus 的优势
Prometheus 的主要优势有:
- 由指标名称和和键/值对标签标识的时间序列数据组成的多维数据模型。
- 强大的查询语言 PromQL。
- 不依赖分布式存储;单个服务节点具有自治能力。
- 时间序列数据是服务端通过 HTTP 协议主动拉取获得的。
- 也可以通过中间网关来推送时间序列数据。
- 可以通过静态配置文件或服务发现来获取监控目标。
- 支持多种类型的图表和仪表盘。
Prometheus 的组件
Prometheus 生态系统由多个组件组成,其中有许多组件是可选的:
- Prometheus Server 作为服务端,用来存储时间序列数据。
- 客户端库用来检测应用程序代码。
- 用于支持临时任务的推送网关。
- Exporter 用来监控 HAProxy,StatsD,Graphite 等特殊的监控目标,并向 Prometheus 提供标准格式的监控样本数据。
- alartmanager 用来处理告警。
- 其他各种周边工具。
其中大多数组件都是用 Go 编写的,因此很容易构建和部署为静态二进制文件。
Prometheus 的架构
Prometheus 的整体架构以及生态系统组件如下图所示:
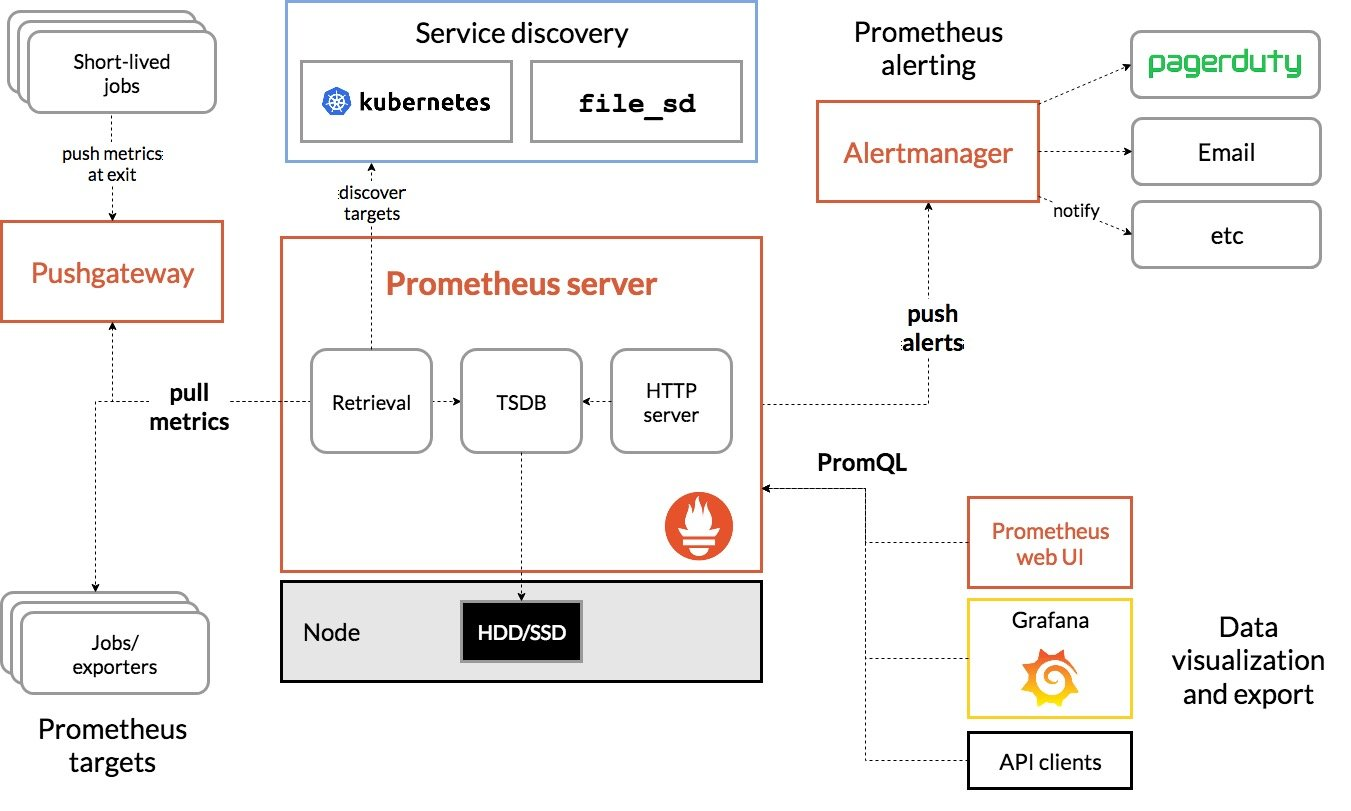
Prometheus Server 直接从监控目标中或者间接通过推送网关来拉取监控指标,它在本地存储所有抓取到的样本数据,并对此数据执行一系列规则,以汇总和记录现有数据的新时间序列或生成告警。可以通过 Grafana 或者其他工具来实现监控数据的可视化。
数据类型
Prometheus 所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB):属于同一指标名称,同一标签集合的、有时间戳标记的数据流。除了存储的时间序列,Prometheus 还可以根据查询请求产生临时的、衍生的时间序列作为返回结果。
指标名称和标签
每一条时间序列由指标名称(Metrics Name)以及一组标签(键值对)唯一标识。其中指标的名称(metric name)可以反映被监控样本的含义(例如,http_requests_total— 表示当前系统接收到的 HTTP 请求总量),指标名称只能由 ASCII 字符、数字、下划线以及冒号组成,同时必须匹配正则表达式[a-zA-Z_:][a-zA-Z0-9_:]*。
样本
在时间序列中的每一个点称为一个样本(sample),样本由以下三部分组成:
- 指标(metric):指标名称和描述当前样本特征的 labelsets;
- 时间戳(timestamp):一个精确到毫秒的时间戳;
- 样本值(value): 一个 folat64 的浮点型数据表示当前样本的值。
表示方式
通过如下表达方式表示指定指标名称和指定标签集合的时间序列:
{=, ...}
例如,指标名称为api_http_requests_total,标签为method=“POST"和handler="/messages"的时间序列可以表示为:
api_http_requests_total{method="POST", handler="/messages"}
这与 OpenTSDB 中使用的标记法相同。
指标类型
Counter(计数器)
Counter 类型代表一种样本数据单调递增的指标,即只增不减,除非监控系统发生了重置。例如,你可以使用 counter 类型的指标来表示服务的请求数、已完成的任务数、错误发生的次数等。counter 主要有两个方法:
//将counter值加1.
Inc()
// 将指定值加到counter值上,如果指定值<0 会panic.
Add(float64)
Counter 类型数据可以让用户方便的了解事件产生的速率的变化,在 PromQL 内置的相关操作函数可以提供相应的分析,比如以 HTTP 应用请求量来进行说明:
//通过rate()函数获取HTTP请求量的增长率
rate(http_requests_total[5m])
//查询当前系统中,访问量前10的HTTP地址
topk(10, http_requests_total)
不要将 counter 类型应用于样本数据非单调递增的指标,例如:当前运行的进程数量(应该用 Guage 类型)。
不同语言关于 Counter 的客户端库使用文档:
Guage(仪表盘)
Guage 类型代表一种样本数据可以任意变化的指标,即可增可减。guage 通常用于像温度或者内存使用率这种指标数据,也可以表示能随时增加或减少的“总数”,例如:当前并发请求的数量。
对于 Gauge 类型的监控指标,通过 PromQL 内置函数 delta() 可以获取样本在一段时间内的变化情况,例如,计算 CPU 温度在两小时内的差异:
dalta(cpu_temp_celsius{host="zeus"}[2h])
你还可以通过PromQL 内置函数 predict_linear() 基于简单线性回归的方式,对样本数据的变化趋势做出预测。例如,基于 2 小时的样本数据,来预测主机可用磁盘空间在 4 个小时之后的剩余情况:
predict_linear(node_filesystem_free{job="node"}[2h], 4 * 3600) < 0
不同语言关于 Guage 的客户端库使用文档:
Histogram(直方图)
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如 CPU 的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统 API 调用的平均响应时间为例:如果大多数 API 请求都维持在 100ms 的响应时间范围内,而个别请求的响应时间需要 5s,那么就会导致某些 WEB 页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在 010ms 之间的请求数有多少而 1020ms 之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram 和 Summary 都是为了能够解决这样问题的存在,通过 Histogram 和 Summary 类型的监控指标,我们可以快速了解监控样本的分布情况。
Histogram 在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(bucket)中,后续可通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图。
Histogram 类型的样本会提供三种指标(假设指标名称为):
样本的值分布在 bucket 中的数量,命名为_bucket{le=”"}。解释的更通俗易懂一点,这个值表示指标值小于等于上边界的所有样本数量。
// 在总共2次请求当中。http 请求响应时间 <=0.005 秒 的请求次数为0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.005",} 0.0 // 在总共2次请求当中。http 请求响应时间 <=0.01 秒 的请求次数为0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.01",} 0.0 // 在总共2次请求当中。http 请求响应时间 <=0.025 秒 的请求次数为0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.025",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.05",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.075",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.1",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.25",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.5",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.75",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="1.0",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="2.5",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="5.0",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="7.5",} 2.0 // 在总共2次请求当中。http 请求响应时间 <=10 秒 的请求次数为 2 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="10.0",} 2.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="+Inf",} 2.0所有样本值的大小总和,命名为_sum。
// 实际含义: 发生的2次 http 请求总的响应时间为 13.107670803000001 秒 io_namespace_http_requests_latency_seconds_histogram_sum{path="/",method="GET",code="200",} 13.107670803000001样本总数,命名为_count。值和_bucket{le="+Inf"}相同。
// 实际含义: 当前一共发生了 2 次 http 请求 io_namespace_http_requests_latency_seconds_histogram_count{path="/",method="GET",code="200",} 2.0
注意
bucket 可以理解为是对数据指标值域的一个划分,划分的依据应该基于数据值的分布。注意后面的采样点是包含前面的采样点的,假设xxx_bucket{…,le=“0.01”}的值为 10,而xxx_bucket{…,le=“0.05”}的值为 30,那么意味着这 30 个采样点中,有 10 个是小于 10 ms 的,其余 20 个采样点的响应时间是介于 10 ms 和 50 ms 之间的。
可以通过 histogram_quantile() 函数来计算 Histogram 类型样本的分位数。分位数可能不太好理解,你可以理解为分割数据的点。我举个例子,假设样本的 9 分位数(quantile=0.9)的值为 x,即表示小于 x 的采样值的数量占总体采样值的 90%。Histogram 还可以用来计算应用性能指标值(Apdex score)。
不同语言关于 Histogram 的客户端库使用文档:
Summary(摘要)
与 Histogram 类型类似,用于表示一段时间内的数据采样结果(通常是请求持续时间或响应大小等),但它直接存储了分位数(通过客户端计算,然后展示出来),而不是通过区间来计算。
Summary 类型的样本也会提供三种指标(假设指标名称为 ):
样本值的分位数分布情况,命名为{quantile=""}。
// 含义:这 12 次 http 请求中有 50% 的请求响应时间是 3.052404983s io_namespace_http_requests_latency_seconds_summary{path="/",method="GET",code="200",quantile="0.5",} 3.052404983 // 含义:这 12 次 http 请求中有 90% 的请求响应时间是 8.003261666s io_namespace_http_requests_latency_seconds_summary{path="/",method="GET",code="200",quantile="0.9",} 8.003261666所有样本值的大小总和,命名为_sum。
// 含义:这12次 http 请求的总响应时间为 51.029495508s io_namespace_http_requests_latency_seconds_summary_sum{path="/",method="GET",code="200",} 51.029495508样本总数,命名为_count。
// 含义:当前一共发生了 12 次 http 请求 io_namespace_http_requests_latency_seconds_summary_count{path="/",method="GET",code="200",} 12.0
现在可以总结一下 Histogram 与 Summary 的异同:
- 它们都包含了_sum和_count指标
- Histogram 需要通过_bucket来计算分位数,而 Summary 则直接存储了分位数的值。
关于 Summary 与 Histogram 的详细用法,请参考 histograms and summaries。
不同语言关于 Summary 的客户端库使用文档:
下载
- 下载地址: https://prometheus.io/download 下载对应版本安装
golang使用prometheus
package main
import (
"log"
"math/rand"
"net/http"
"time"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var (
cpuTemp = prometheus.NewGauge(prometheus.GaugeOpts{
Name: "cpu_temperature_celsius",
Help: "Current temperature of the CPU.",
})
hdFailures = prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "hd_errors_total",
Help: "Number of hard-disk errors.",
},
[]string{"device", "service"},
)
)
func init() {
// Metrics have to be registered to be exposed:
prometheus.MustRegister(cpuTemp)
prometheus.MustRegister(hdFailures)
}
func main() {
go func() {
for {
val := rand.Float64() * 100
cpuTemp.Set(val)
hdFailures.With(prometheus.Labels{
"device": "/dev/sda",
"service": "hello.world",
}).Inc()
time.Sleep(time.Second)
}
}()
// The Handler function provides a default handler to expose metrics
// via an HTTP server. "/metrics" is the usual endpoint for that.
http.Handle("/metrics", promhttp.Handler())
log.Fatal(http.ListenAndServe(":8080", nil))
}
执行代码 并访问