kubernetes CNI(Container Network Interface)
为什么需要 CNI
在 kubernetes 中,pod 的网络是使用 network namespace 隔离的,但是我们有时又需要互相访问网络,这就需要一个网络插件来实现 pod 之间的网络通信。CNI 就是为了解决这个问题而诞生的。CNI 是 Container Network Interface 的缩写,它是一个规范,定义了容器运行时如何配置网络。CNI 插件是实现了 CNI 规范的二进制文件,它可以被容器运行时调用,来配置容器的网络。
CNI 规范详解
CNI 的设计理念
CNI 的设计非常简洁,它只关注两件事:
- 容器创建时:为容器的网络命名空间配置网络
- 容器删除时:清理容器的网络资源
CNI 采用了插件化的架构,这使得它具有以下优势:
- 灵活性:不同的环境可以选择不同的网络实现
- 可扩展性:容易添加新的网络方案
- 语言无关:CNI 插件可以用任何语言实现,只要遵循规范即可
CNI 插件的工作流程
当 kubelet 需要为 pod 配置网络时,整个流程如下:
- kubelet 调用 CRI(Container Runtime Interface)创建 pod 的 sandbox 容器
- CRI 实现(如 containerd、CRI-O)创建 network namespace
- CRI 读取 CNI 配置文件(通常在
/etc/cni/net.d/) - CRI 根据配置调用相应的 CNI 插件(通常在
/opt/cni/bin/) - CNI 插件 为容器配置网络(创建 veth pair、配置 IP、设置路由等)
- CNI 插件 返回结果(IP 地址、网关、DNS 等信息)
CNI 配置文件示例
CNI 的配置文件是 JSON 格式,一个典型的配置如下:
{
"cniVersion": "0.4.0",
"name": "mynet",
"type": "bridge",
"bridge": "cni0",
"isGateway": true,
"ipMasq": true,
"ipam": {
"type": "host-local",
"subnet": "10.244.0.0/16",
"routes": [
{ "dst": "0.0.0.0/0" }
]
}
}
主要字段说明:
cniVersion:CNI 规范版本name:网络名称type:插件类型(如 bridge、ipvlan、macvlan 等)ipam:IP 地址管理配置
CNI 插件类型
CNI 插件主要分为三类:
Main 插件:用于创建网络接口
bridge:创建网桥ipvlan:添加 ipvlan 接口macvlan:添加 macvlan 接口ptp:创建点对点连接
IPAM 插件:用于 IP 地址分配
host-local:在本地维护 IP 地址池dhcp:通过 DHCP 服务器分配 IPstatic:使用静态 IP
Meta 插件:用于调用其他插件或修改配置
flannel:从 flannel daemon 获取配置tuning:调整网络接口参数portmap:配置端口映射bandwidth:限制带宽
Docker 网络
基础
计算机五层网络如下:
如果我们想把 pod 中的网络对外,首先想到的就是七层代理,比如nginx,但是我们并不知道 pod 里的网络一定是 http,甚至他可能不是tcp。所以我们像做一些网络操作,就不能在五层做了,只能在二三四层做。
Docker 实验
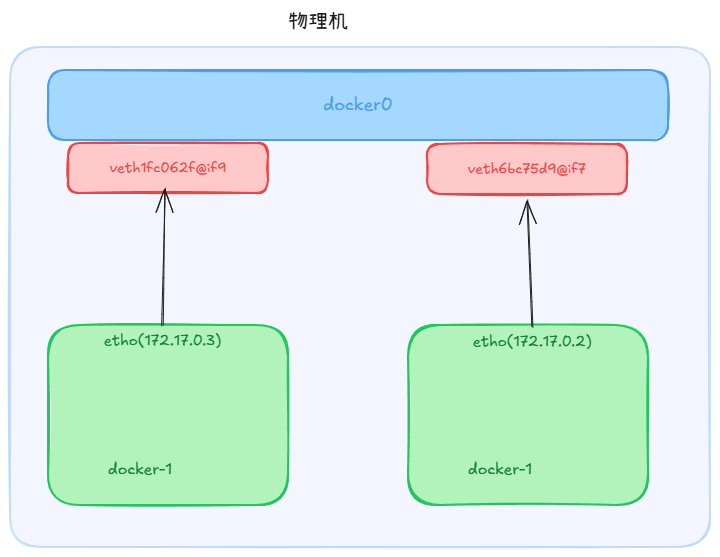
当我们在物理机上启动 docker daemon 不需要启动任何容器的时候,使用 ip a 命令查看网卡,发现多了一个 docker0
4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:9b:65:e1:01 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
docker0 是一个 linux Bridge 设备,这个可以理解成一个虚拟的交换机,用来做二层网络的转发。当我们启动一个容器的时候,docker 会为这个容器创建一个 veth pair 设备,一个端口挂载在容器的 network namespace 中,另一个端口挂载在 docker0 上。这样容器就可以和 docker0 上的其他容器通信了。
docker run -d --rm -it ubuntu:22.04 sleep 3000
在物理机上查看 ip a
8: veth6bc75d9@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether d6:87:ca:5c:54:51 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::d487:caff:fe5c:5451/64 scope link
valid_lft forever preferred_lft forever
docker 容器里面 ip a
7: eth0@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
再启动一个 docker
docker run --name test -d --rm -it ubuntu:22.04 sleep 3000
# ip a
9: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.3/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
这样两个容器就可以通过 docker0 通信了。
root@b19a3dc4b32d:/# ping 172.17.0.2
PING 172.17.0.2 (172.17.0.2) 56(84) bytes of data.
64 bytes from 172.17.0.2: icmp_seq=1 ttl=64 time=0.055 ms
通信方式
常见 CNI 插件对比
在了解具体的网络实现之前,我们先来看看业界常用的 CNI 插件及其特点:
CNI 网络
当两个 pod 在同一 node 上的时候,我们可以使用像上述 docker 的 bridge 的方式通信是没问题的。但是 kubernetes 是多节点的集群,当 pod 在不同的 node 上的时候,直接通信肯定不行了,这时候我们需要一些办法来解决这个问题。
UDP 封包
当 pod 在不同节点上的时候,两个 pod 不可以直接通信,那最简单的方式就是通过 udp 封包,把整个网络包使用 udp 封包起来,然后第二个节点再解包,然后发给网桥。
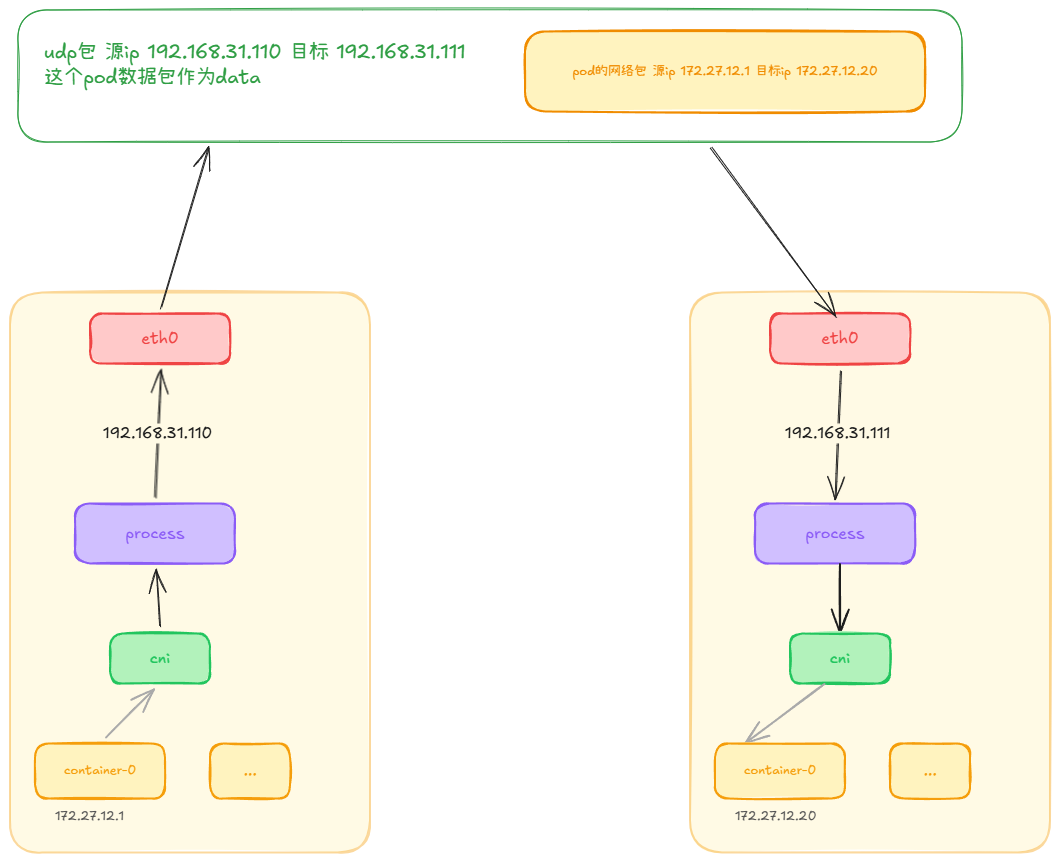
整个过程就是 node1 上的 pod 把网络包封装,然后由于 process 再封装发给 node2,node2 再解包,然后发给 pod2。
process 是 cni 实现的进程,很多 cni 都实现 udp 封包的方式,比如 flannel,cailco 等。
至于我们怎么知道目标 ip (pod 的 ip) 是在哪台主机上,这个就有很多中方式了,比如把每台机器发配 ip 分配不同的网段,甚至于把这些对应关系写到 etcd 中。
VXLAN
上述的 udp 封包方式,是可以满足基本需求但是。cni 创建的 process 进程是一个用户态的进程,每个包要在 node1 上从内核态 copy 到用户态,然后再封包,再 copy 到内核态,再发给 node2,再从内核态 copy 到用户态,再解包,再 copy 到内核态,再发给 pod2。这样的方式效率很低。所以我们使用一种更加高效的方式,就是 vxlan。
VXLAN 是什么?
VXLAN(Virtual Extensible LAN)是一种网络虚拟化技术,用于解决大规模云计算环境中的网络隔离、扩展性和灵活性问题。VXLAN 允许网络工程师在现有的网络架构上创建一个逻辑网络层,这可以使得数据中心的网络设计变得更加灵活和可扩展。
为什么性能会高?
VXLAN 是在内核态实现的,原理和 udp 封包一样,只不过是在内核态实现的,数据包不会在内核态和用户态之间 copy,所以效率会高很多。
ip 路由
就算是 vxlan,也是需要封包和解包的,这样的方式效率还是不够高,所以我们可以使用 ip 路由的方式。
ip 路由故名思意,就是使用路由表来实现 pod 之间的通信。这样的方式效率最高,但是配置比较复杂,需要配置路由表。
而且路由表跳转是二层网络实现的,所以又要要求所有 node 在同一个二层网络中。
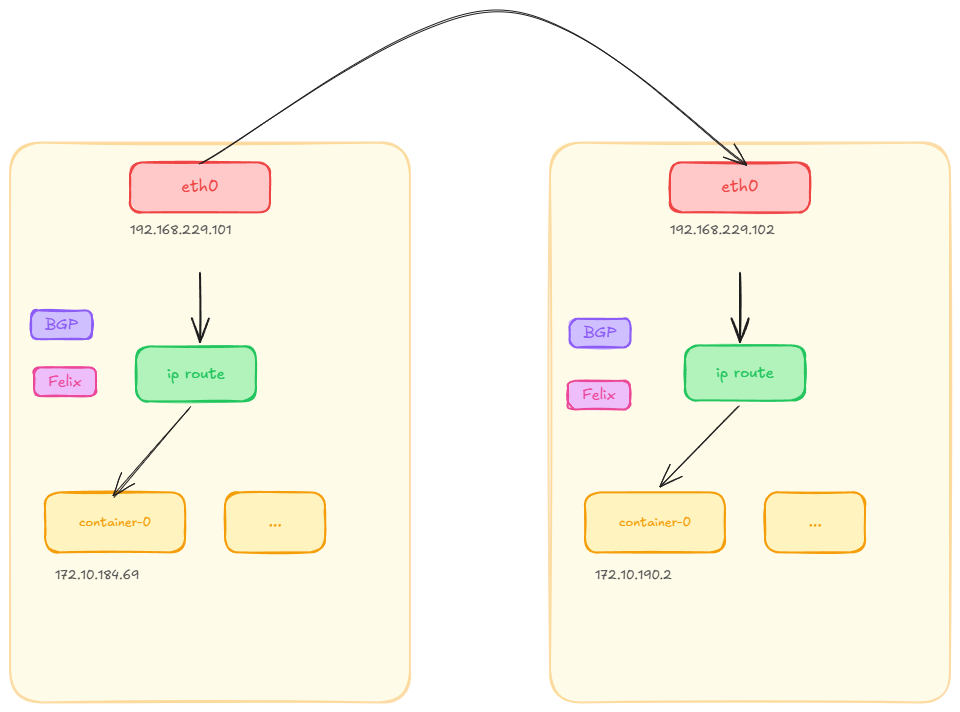
查看 node1 上的 container 的是设备
ip a
2: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 66:5e:d8:8d:86:ba brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.10.184.69/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::645e:d8ff:fe8d:86ba/64 scope link
valid_lft forever preferred_lft forever
这个和主机上是对应的是一个 veth pair 设备,一个端口挂载在容器的 network namespace 中,一边挂载在主机上。
# 主机
ip a
10: calia78b8700057@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-0da431c8-dd8b-ca68-55e6-40b04acf78d6
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
当 pod 中的数据包来到主机 查看 node1 上的路由表 会命中一下这条路由 这条的意思是跳到192.168.229.102节点使用 ens33 设备
ip r
172.10.190.0/26 via 192.168.229.102 dev ens33 proto bird
当 数据包来到 node2 上的时候 我们看下 node2 的路由表
ip r
172.10.190.2 dev calie28ee63d6b0 scope link
ip a
7: calie28ee63d6b0@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-dd892c92-1826-f648-2b8c-d22618311ca9
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
这个设备是 veth pair 设备,对应的容器内的
ip a
2: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether fa:a6:2f:97:58:28 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.10.190.2/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::f8a6:2fff:fe97:5828/64 scope link
valid_lft forever preferred_lft forever
这样node2上的 172.10.190.2 pod 就可以收到数据包了。
路由跳转
路由跳转是怎么实现的?
路由跳转是通过路由表来实现的,它作用在二层上,所以当跳转的时候,直接修改数据包的目标 mac 地址(如果不知道的话是使用 ARP 协议获得)。
所以当我们访问百度的时候,获得百度的ip的时候,数据包会经过很多路由器,每个路由器都会修改数据包的目标 mac 地址,这样数据包就可以到达百度的服务器了。
Felix
那么主机上的路由表是怎么来的呢?
这个就是 cni 的实现了,cni 会调用 felix 这个进程,felix 会根据 cni 的配置来配置路由表。
ip in ip
刚才也说过了,ip 路由是最高效的,是因为它作用在二层网络上,这就需要保证所有的 node 在同一个二层网络上。但是有时候我们的 node 不在同一个二层网络上,这时候我们可以使用 ip in ip。
简单来说就是如果 node 之间在一个二层网络上,那么就直接使用 ip 路由,如果不在,那么就使用 ip in ip,把数据包封装起来,然后再发给对应的 node。
ip-in-ip 是一种隧道技术,它将一个 IP 数据包封装在另一个 IP 数据包中,这样就可以在一个 IP 网络上传输另一个 IP 网络的数据包。
172.10.180.0/24 via 192.168.228.28 tunl0
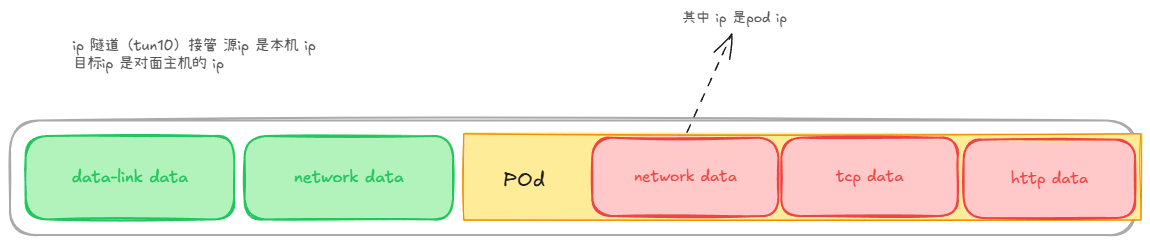
这个只是在源数据包的三层上再封装一层 IP 头部。相比 VXLAN(封装完整的二层以太网帧),IP-in-IP 只封装 IP 头,开销更小。这样性能方面稍微比使用了 UDP 的 VXLAN 要好一点。但是最好还是避免使用 IP-in-IP,尽量保证 node 在同一个二层网络上。
我怎么知道 Pod IP 在哪台机器上?
在 Kubernetes 集群中,Pod IP 是一个 虚拟的、动态分配的地址。 当一个数据包需要从一个 Pod 发送到另一个 Pod 时,网络系统必须知道:
目标 Pod IP 实际运行在哪一台 Node 上?
只有解决了这个问题,数据包才能被正确地转发到对应的节点。 常见的实现思路主要有以下三种。
1.维护 Pod IP → Node 的映射关系
最直接的方式,是显式维护 Pod IP 与 Node 之间的对应关系。
例如:
- 将 Pod IP → Node IP 的映射存储到
- 数据库
- etcd
- Kubernetes CRD(自定义资源)
- 当需要转发流量时,先查询映射关系,再决定下一跳
这种方式的优点是逻辑直观、可控性强,但缺点也很明显:
- Pod 创建、销毁频繁,映射关系变化快
- 需要额外的控制面组件来维护一致性
- 查询与同步本身会带来额外开销
因此,这种方案在大规模集群中实现成本较高。
2.以 Node 为单位划分 Pod CIDR
另一种更常见、也更高效的方式,是按 Node 维度分配 Pod 网段。
例如:
- Node A:172.16.100.0/26
- Node B:172.16.100.64/26
- Node C:172.16.100.128/26
在这种模式下:
- 每个 Node 只负责一个固定的 Pod CIDR
- 只要看到目标 IP 落在哪个 CIDR 中,就能确定对应的 Node
- 不需要维护单个 Pod 级别的映射关系
这种方案的优势在于:
- 路由规则简单
- 查询效率高
- 非常适合 Host-Gateway、直连路由 等网络模型
这也是 Kubernetes 中 最常见的 Pod IP 定位方式。
3.通过 BGP 动态交换路由信息
在更复杂或规模更大的集群中,通常会引入 BGP(Border Gateway Protocol) 来动态分发路由。
其核心思想是:
- 每个 Node 将自己负责的 Pod CIDR 通过 BGP 广播出去
- 其他 Node 或上游物理网络设备自动学习这些路由
- 当 Pod 迁移或节点变化时,路由信息可以自动收敛
这种方式的特点是:
- 不需要集中维护映射关系
- 路由自动学习、自动更新
- 可与数据中心网络或云网络无缝打通
像 Calico(BGP 模式) 就大量使用了这种方案。
当然,代价是:
- 对网络设备和运维能力要求较高
- 排错和理解成本相对更大
Calico encapsulation
- None: 纯路由
- IPIP
- VXLAN
- IPIPCrossSubnet
- VXLANCrossSubnet IPIPCrossSubnet 和 VXLANCrossSubnet 为同一网段的 node 用路由转发通信 ,否则使用 ipip (vxlan)
eBPF
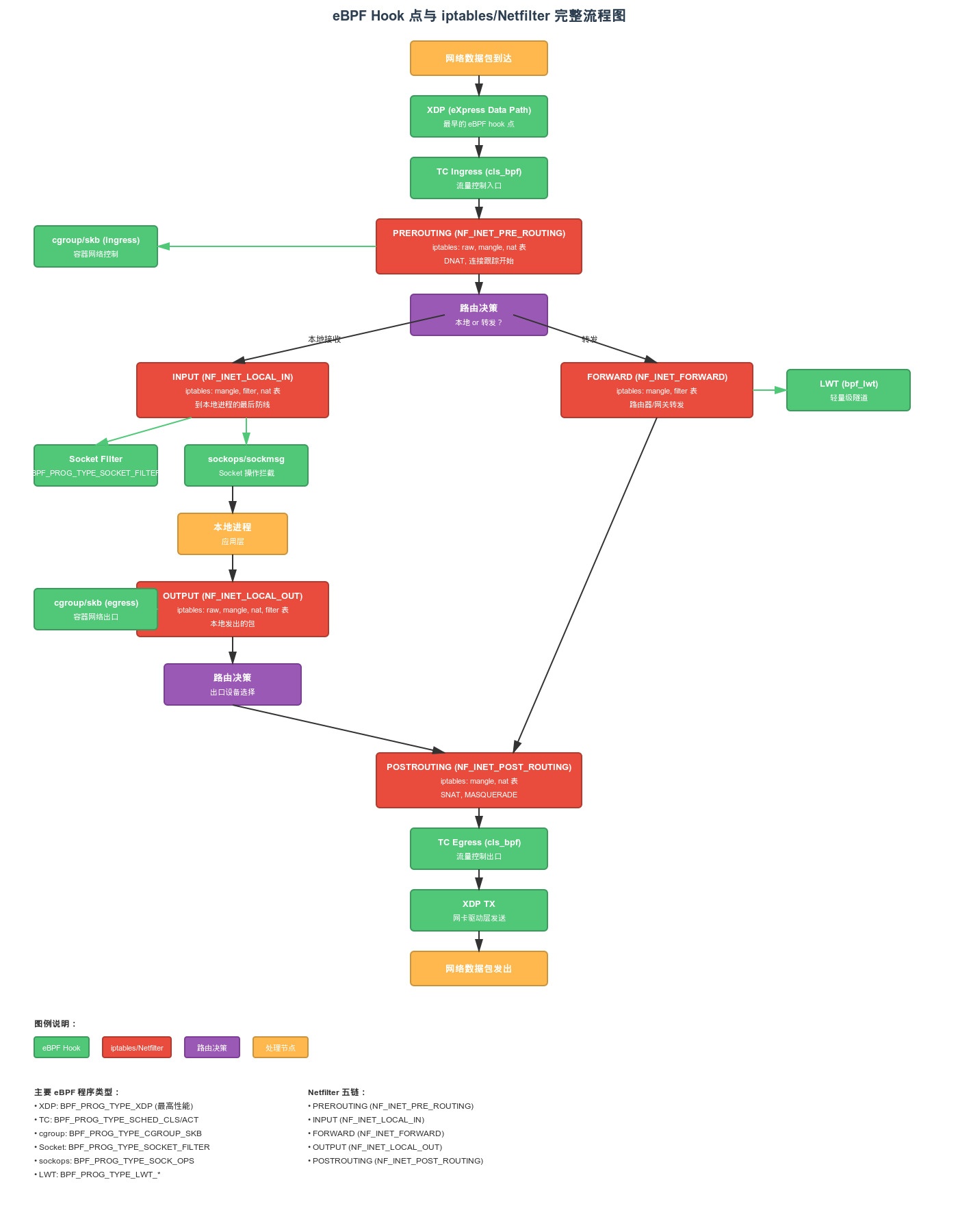
为什么需要 eBPF ?
在传统的 Kubernetes 网络模型中,流量转发高度依赖内核的 Netfilter (iptables/nftables)。但随着集群规模的扩大,这种机制暴露了两个核心痛点:
- 性能瓶颈:每一个数据包经过节点(Node)时,都需要在 Netfilter 和 Conntrack 复杂的规则链中逐一匹配。这种“全量遍历”在大规模 Service 环境下会带来显著的延迟。
- 调试困难:iptables 规则像一个黑盒,在大流量场景下追踪一个包的去向极其痛苦,可观测性较差。
Calico 在 VXLAN (CrossSubnet) 模式下如何利用 eBPF?
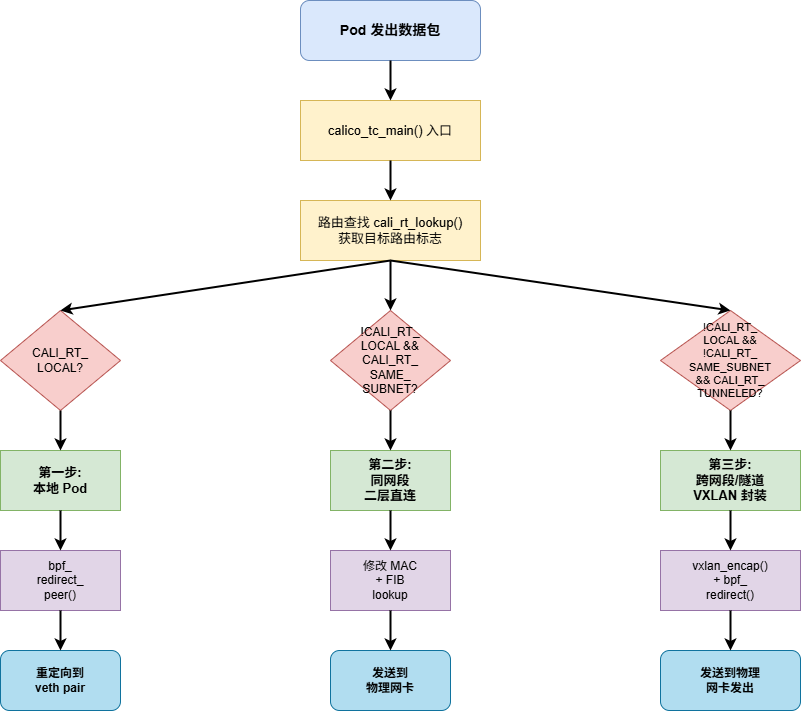
在开启 eBPF 模式后,Calico 会绕过传统的 Netfilter 路径,直接在 tc (Traffic Control) hook (veth-pair host端网卡 egress) 点挂载 eBPF 程序,实现对 Pod 流量的“精准劫持”和快速转发。 核心转发逻辑分解 当一个 Pod 发出的数据包到达主机的 eBPF 程序时,它会进行以下“三步走”的逻辑判断:
第一步:判断是否为本地流量
- 如果目标容器就在当前节点上,eBPF 直接将包重定向到对应的 veth pair
第二步:判断是否为同网段(二层直连)
- eBPF 会修改数据包的二层 MAC 地址,直接通过默认物理网卡发送出去。
第三步:跨网段转发(VXLAN 封包)
- eBPF 自动进行 UDP 封包(符合 VXLAN 格式)。
- 外层封包格式
- UDP 头部:目标端口通常为 4789(标准 VXLAN 端口)
- VXLAN 头部:包含 VNI(Virtual Network Identifier)
- 外层 IP 头部:
- 源 IP:当前物理节点的网卡 IP
- 目标 IP:目标 Pod 所在的远端物理节点网卡 IP。
- 外层 MAC 头部:
- 源 MAC:当前物理网卡的 MAC 地址。
- 目标 MAC:下一跳(通常是本地网关)的 MAC 地址。
- 封装完成后,直接将隧道包转交给物理网卡发出。
calico felix 代码
入口
/* calico_tc_main is the main function used in all of the tc programs. It is specialised
* for particular hook at build time based on the CALI_F build flags.
*/
SEC("tc")
int calico_tc_main(struct __sk_buff *skb)
{
// 检查是否为环回流量
if (CALI_F_LO && CALI_F_TO_HOST) {
/* Do nothing, it is a packet that just looped around. */
return TC_ACT_UNSPEC;
}
finalize:
return forward_or_drop(ctx);
}
/* 尝试将数据包重定向到同节点的 Pod(peer) */
static CALI_BPF_INLINE int try_redirect_to_peer(struct cali_tc_ctx *ctx)
{
// 检查是否启用 peer 重定向
bool redirect_peer = GLOBAL_FLAGS & CALI_GLOBALS_REDIRECT_PEER;
// ......
rc = bpf_redirect_peer(state->ct_result.ifindex_fwd, 0);
//......
}
// 1. 执行 FIB 查找
*fib_params(ctx) = (struct bpf_fib_lookup) {
.family = 2, // AF_INET
.ifindex = ctx->skb->ifindex,
.ipv4_src = state->ip_src,
.ipv4_dst = state->ip_dst,
};
rc = bpf_fib_lookup(ctx->skb, fib_params(ctx), sizeof(struct bpf_fib_lookup),
BPF_FIB_LOOKUP_SKIP_NEIGH);
// 2. 赋值
nh_params.ipv4_nh = fib_params(ctx)->ipv4_dst;
// 3. 使用 bpf 函数直接转发
rc = bpf_redirect_neigh(fib_params(ctx)->ifindex, &nh_params, ...);
// 1. VXLAN 封装
if (vxlan_encap(ctx, &STATE->ip_src, &STATE->ip_dst, vxlan_src_port)) {
deny_reason(ctx, CALI_REASON_ENCAP_FAIL);
goto deny;
}
// 2. 设置隧道元数据
struct bpf_tunnel_key key = {
.tunnel_id = OVERLAY_TUNNEL_ID,
.remote_ipv4 = bpf_htonl(dest_rt->next_hop), // 下一跳 VTEP IP
};
bpf_skb_set_tunnel_key(ctx->skb, &key, size, BPF_F_ZERO_CSUM_TX);
// 3. 重定向到物理网卡
rc = bpf_redirect(state->ct_result.ifindex_fwd, 0);
/* VXLAN 封装函数
* ctx: 上下文
* ip_src: 外层源 IP
* ip_dst: 外层目标 IP
* src_port: VXLAN 源端口
*/
static CALI_BPF_INLINE int vxlan_encap(struct cali_tc_ctx *ctx,
__be32 *ip_src, __be32 *ip_dst,
__u16 src_port)
{
// ....
}