Calico 二进制执行流程解析
Calico CNI 二进制执行流程分析
简介
在 Kubernetes CNI 插件调用流程 中,介绍了 cni 是怎么通过 config 文件调用 cni 的二进制命令配置网络的,本文将以 calico cni 插件为例,分析一下 calico 二进制执行流程。
本文基于 calico v3.31.4 版本进行分析,其他版本可能会有一些差异。
calico 添加网络的流程
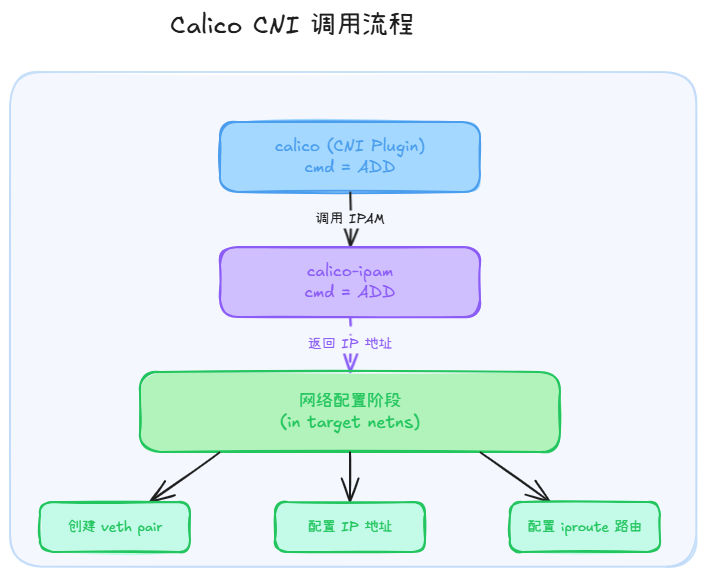
代码流程
入口:main 函数
calico 把多个 cni 插件打进了同一个二进制,通过判断 os.Args[0](也就是二进制文件本身的文件名)来决定走哪个插件逻辑。这是一个很常见的多路复用技巧,比如 busybox 也是这么玩的——同一个二进制,软链接不同的名字,行为就不一样。
func main() {
_, filename := filepath.Split(os.Args[0])
switch filename {
case "calico", "calico.exe":
plugin.Main(buildinfo.Version)
case "calico-ipam", "calico-ipam.exe":
ipamplugin.Main(buildinfo.Version)
default:
panic("Unknown binary name: " + filename)
}
}
plugin.Main 里注册了三个 CNI 标准回调:Add、Del 和 Check。CNI 规范要求插件实现这三个操作,kubelet 在创建/删除 Pod 网络时会分别调用对应的操作。
func Main(version string) {
// ......
funcs := skel.CNIFuncs{
Add: cmdAdd, // 添加网络的函数
Del: cmdDel,
Check: cmdDummyCheck,
}
// ......
}
cmdAdd:添加网络
cmdAdd 是整个流程的起点。calico 支持多种 orchestrator(编排器),比如 Kubernetes、Mesos 等,这里做了一个分支判断。在 k8s 场景下,绝大多数情况都会走 CmdAddK8s。
func cmdAdd(args *skel.CmdArgs) (err error) {
// ......
// 配置一些参数,比如 MTU 等
// 如果是 k8s 调用,则调用 k8s 的 cmdAddK8s 函数
if wepIDs.Orchestrator == api.OrchestratorKubernetes {
if result, err = k8s.CmdAddK8s(ctx, args, conf, *wepIDs, calicoClient, endpoint); err != nil {
return
}
} else {
// ......
}
// ......
return
}
CmdAddK8s:K8s 场景下的网络配置
这个函数负责处理 k8s Pod 的网络配置,逻辑上分两大块:
- IP 地址分配:根据 Pod 上是否有特定 annotation 来决定走哪种 IPAM 策略
- 网络配置:调用
DoNetworking把 veth pair、路由等都配置好
关于 IP 分配,calico 提供了三种模式,通过 annotation 来区分:
- 默认模式(没有 annotation):走 calico 自带的 IPAM,由 calico-ipam 来分配
- ipAddrsNoIpam:完全绕过 IPAM,直接用 annotation 里指定的 IP,适合外部有独立 IPAM 系统的场景
- ipAddrs:用 annotation 里指定的 IP,但生命周期仍然由 calico IPAM 托管
func CmdAddK8s(ctx context.Context, args *skel.CmdArgs, conf types.NetConf, epIDs utils.WEPIdentifiers, calicoClient calicoclient.Interface, endpoint *libapi.WorkloadEndpoint) (*cniv1.Result, error) {
// ......
if conf.Policy.PolicyType == "k8s" {
// 配置一些标签和注解
}
ipAddrsNoIpam := annot["cni.projectcalico.org/ipAddrsNoIpam"]
ipAddrs := annot["cni.projectcalico.org/ipAddrs"]
switch {
case ipAddrs == "" && ipAddrsNoIpam == "":
// 调用 IPAM 插件进行 IP 地址分配
result, err = utils.AddIPAM(conf, args, logger)
if err != nil {
return nil, err
}
case ipAddrs != "" && ipAddrsNoIpam != "":
// 报错,不能同时设置两个 annotation
case ipAddrsNoIpam != "":
// 不调用 IPAM,直接使用 annotation 里的 IP
case ipAddrs != "":
// 调用 IPAM 管理生命周期,但 IP 从 annotation 里取
}
// 做网络配置
hostVethName, contVethMac, err := d.DoNetworking(
ctx, calicoClient, args, result, desiredVethName, routes, endpoint, annot)
if err != nil {
logger.WithError(err).Error("Error setting up networking")
releaseIPAM()
return nil, err
}
// 配置 result
// ......
return result, nil
}
DoNetworking & DoWorkloadNetnsSetUp:配置 veth 和路由
这一层是真正动手操作网络的地方,核心是创建 veth pair,并在容器 netns 内配置 IP 和路由。
veth pair 是 Linux 内核提供的一种虚拟网络设备,两端成对出现,数据从一端进,从另一端出。calico 用它来打通容器内部和宿主机之间的网络通路:一端在容器 netns 里(通常叫 eth0),另一端在宿主机的 root netns 里(名字类似 cali1a2b3c4d)。
func (d *linuxDataplane) DoNetworking(
ctx context.Context,
calicoClient calicoclient.Interface,
args *skel.CmdArgs,
result *cniv1.Result,
desiredVethName string,
routes []*net.IPNet,
endpoint *api.WorkloadEndpoint,
annotations map[string]string,
) (hostVethName, contVethMAC string, err error) {
// ......
contVethMAC, err = d.DoWorkloadNetnsSetUp(
hostNlHandle,
args.Netns,
result.IPs,
args.IfName,
hostVethName,
routes,
annotations,
)
// ......
return hostVethName, contVethMAC, err
}
DoWorkloadNetnsSetUp 会进入容器的 network namespace 来操作,这里用的是 ns.WithNetNSPath,它内部通过 setns 系统调用切换 netns。
func (d *linuxDataplane) DoWorkloadNetnsSetUp(
hostNlHandle *netlink.Handle,
netnsPath string,
ipAddrs []*cniv1.IPConfig,
contVethName string,
hostVethName string,
routes []*net.IPNet,
annotations map[string]string,
) (contVethMAC string, err error) {
// 如果宿主机上同名的 hostVeth 已经存在(比如 Pod 重建),先清掉
if oldHostVeth, err := hostNlHandle.LinkByName(hostVethName); err == nil {
if err = hostNlHandle.LinkDel(oldHostVeth); err != nil {
return "", fmt.Errorf("failed to delete old hostVeth %v: %v", hostVethName, err)
}
d.logger.Infof("Cleaning old hostVeth: %v", hostVethName)
}
err = ns.WithNetNSPath(netnsPath, func(hostNS ns.NetNS) error {
la := netlink.NewLinkAttrs()
la.Name = contVethName
la.MTU = d.mtu
la.NumTxQueues = d.queues
la.NumRxQueues = d.queues
// 创建 veth pair:容器端叫 contVethName,宿主机端叫 hostVethName
veth := &netlink.Veth{
LinkAttrs: la,
PeerName: hostVethName,
PeerNamespace: netlink.NsFd(int(hostNS.Fd())),
}
if err := netlink.LinkAdd(veth); err != nil {
d.logger.Errorf("Error adding veth %+v: %s", veth, err)
return err
}
hostVeth, err := hostNlHandle.LinkByName(hostVethName)
if err != nil {
err = fmt.Errorf("failed to lookup %q: %v", hostVethName, err)
return err
}
// ......
// 根据 IP 版本设置掩码(容器 IP 用 /32 或 /128,而不是子网掩码)
var hasIPv4, hasIPv6 bool
for _, addr := range ipAddrs {
if addr.Address.IP.To4() != nil {
hasIPv4 = true
addr.Address.Mask = net.CIDRMask(32, 32)
} else if addr.Address.IP.To16() != nil {
hasIPv6 = true
addr.Address.Mask = net.CIDRMask(128, 128)
}
}
if hasIPv4 {
// 添加一条指向 169.254.1.1 的链路路由
gw := net.IPv4(169, 254, 1, 1)
gwNet := &net.IPNet{IP: gw, Mask: net.CIDRMask(32, 32)}
err := netlink.RouteAdd(
&netlink.Route{
LinkIndex: contVeth.Attrs().Index,
Scope: netlink.SCOPE_LINK,
Dst: gwNet,
},
)
if err != nil {
return fmt.Errorf("failed to add route inside the container: %v", err)
}
for _, r := range routes {
if r.IP.To4() == nil {
continue
}
if err = ip.AddRoute(r, gw, contVeth); err != nil {
return fmt.Errorf("failed to add IPv4 route for %v via %v: %v", r, gw, err)
}
}
}
// ......
return nil
})
if err != nil {
d.logger.Errorf("Error creating veth: %s", err)
return "", err
}
return
}
为什么路由网关是 169.254.1.1?
这是 calico 的一个经典设计,经常让初次接触的人感到困惑。在容器里看到的路由表大概是这样的:
ip r
default via 169.254.1.1 dev eth0
169.254.1.1 dev eth0 scope link
这里有几个关键点:
- 169.254.1.1 是一个虚假的网关地址。这个 IP 根本不存在于任何真实的网络接口上,它只是一个"占位符"。
- 所有流量都指向这个虚假网关。容器内部的默认路由和其他路由都 via 169.254.1.1,然后 169.254.1.1 本身是 scope link,意思是通过 eth0 直连可达,不需要再走下一跳。
- 宿主机上的 veth 开启了 proxy ARP。当容器发 ARP 请求问 169.254.1.1 是谁的 MAC 时,宿主机上的 caliXXXX 接口会用自己的 MAC 来应答(proxy arp)。这样容器就把数据包发给了 veth pair 的另一端,也就是宿主机。
- 宿主机上的路由表接管后续转发。数据包到了宿主机之后,由宿主机的路由表决定下一步怎么走,是直接投递还是通过 BGP 路由到其他节点。
这样设计的好处是:不需要在容器里配置任何真实的网关 IP,每个节点的 veth 都用同一个虚假地址,路由配置非常统一,也不会跟实际的网络地址产生冲突。
calico-ipam
IPAM 部分是另一个二进制(或者同一个二进制但文件名是 calico-ipam),负责 IP 地址的分配和回收。
整体结构:Block 是核心
calico IPAM 的设计里有一个很重要的概念叫 Block。calico 不是给每个 Pod 单独分配 IP,而是先把大的 IP Pool(比如 192.168.0.0/16)切分成一块一块的 Block(默认 /26,也就是 64 个 IP),然后把每个 Block 分配给某个节点,节点再从自己的 Block 里给 Pod 分 IP。
这样设计的好处是:
- 减少 API Server 压力:一个 Block 里 64 个 IP,只需要一次 CRD 操作就能表示
- 配合 BGP 路由聚合:节点可以把自己拥有的 Block 作为一条路由在 BGP 里广播,减少路由条目数量
- 分配效率高:同一个节点的 IP 通常在同一个 Block 里,不需要全局锁
Block 对应的 CRD
在 k8s 里,每个 Block 是一个 IPAMBlock CRD 资源,可以用 calicoctl 或者 kubectl 查看:
# 查看所有 IPAMBlock
calicoctl get ipamblock
# 或者
kubectl get ipamblocks.crd.projectcalico.org -o yaml
# 查看某个具体的 block
calicoctl get ipamblock 192.168.1.0-26 -o yaml
一个典型的 IPAMBlock 长这样:
apiVersion: crd.projectcalico.org/v1
kind: IPAMBlock
metadata:
name: 192-168-1-0-26
spec:
affinity: host:node-1 # 这个 block 归属于 node-1
cidr: 192.168.1.0/26
allocations: # 64 个槽位,nil 表示未分配
- null
- 0 # 索引 0 的属性
- null
- 1
# ...
attributes: # 每个属性记录是哪个 Pod 在用
- handle_id: k8s-pod-namespace.podname
secondary:
node: node-1
pod: podname
namespace: namespace
unallocated: # 还没分配出去的偏移量列表
- 0
- 2
- 5
# ...
除了 IPAMBlock,calico 还维护了 IPAMHandle 资源,用来记录某个 handle(通常对应一个 Pod)持有哪些 IP,方便回收时做反向查找:
calicoctl get ipamhandle
kubectl get ipamhandles.crd.projectcalico.org
cmdAdd:IPAM 的入口
func cmdAdd(args *skel.CmdArgs) error {
// ......
autoAssignWithLock := func(calicoClient client.Interface, assignArgs ipam.AutoAssignArgs) (*ipam.IPAMAssignments, *ipam.IPAMAssignments, error) {
// 先获取一个全局的文件锁,防止同一台机器上多个 CNI 调用并发修改 IPAM 状态
unlock := acquireIPAMLockBestEffort(conf.IPAMLockFile)
defer unlock()
ctx, cancel := context.WithTimeout(context.Background(), 90*time.Second)
defer cancel()
// 正式分配 IP
return calicoClient.IPAM().AutoAssign(ctx, assignArgs)
}
v4Assignments, v6Assignments, err := autoAssignWithLock(calicoClient, assignArgs)
// ......
}
这里有个细节值得注意:calico 在调用 AutoAssign 之前,会先拿一个本地的文件锁(IPAMLockFile)。这是因为同一台节点上可能同时有多个容器在启动(比如 DaemonSet 滚动更新),如果并发请求打到 datastore 上,很容易出现竞态条件。文件锁是一个粗粒度但有效的保护手段。
AutoAssign:分配 IP 的核心逻辑
func (c ipamClient) AutoAssign(ctx context.Context, args AutoAssignArgs) (*IPAMAssignments, *IPAMAssignments, error) {
// ......
if args.Num4 != 0 {
v4ia, err = c.autoAssign(ctx, args.Num4, args.HandleID, args.Attrs, args.IPv4Pools, 4, hostname, args.MaxBlocksPerHost, args.HostReservedAttrIPv4s, args.IntendedUse, args.Namespace)
}
// ......
return v4ia, v6ia, nil
}
findOrClaimBlock:找到或申领一个 Block
这是 IPAM 里最复杂也最关键的部分。每次分配 IP 时,calico 需要先确定从哪个 Block 里拿。大致流程是:
- 优先找当前节点已有亲和性的 Block:如果这个节点之前已经被分配过 Block(即
spec.affinity: host:当前节点),优先从这些 Block 里找空余的槽位 - 如果没有可用 Block 或已有 Block 都满了:尝试从 IP Pool 里划出一个新的
/26Block,写入 datastore,并把 affinity 设置为当前节点 - 如果超过了节点最大 Block 数限制(
MaxBlocksPerHost):就只能尝试从其他节点"借"Block 里的空余 IP(跨节点分配,路由会更复杂)
这里用到了乐观锁机制——分配 Block 时会做 CAS(Compare-And-Swap)操作,如果有并发冲突,会重试,重试次数由 datastoreRetries 控制。
func (c ipamClient) autoAssign(ctx context.Context, num int, handleID *string, ...) (*IPAMAssignments, error) {
for len(ia.IPs) < num {
rem := num - len(ia.IPs)
if maxNumBlocks > 0 && numBlocksOwned >= maxNumBlocks {
s.allowNewClaim = false
}
// 找到一个可用的 Block,或者申领一个新的
b, newlyClaimed, err := s.findOrClaimBlock(ctx, 1)
for i := 0; i < datastoreRetries; i++ {
newIPs, err := c.assignFromExistingBlock(ctx, b, rem, handleID, attrs, affinityCfg, config.StrictAffinity, reservations)
if err != nil {
// 出现竞争冲突,重试
// ......
}
rem = num - len(ia.IPs)
break
}
}
}
从 Block 里分配具体 IP
找到 Block 之后,具体的 IP 分配在 autoAssign(Block 级别)里完成。逻辑很直接:遍历 Unallocated 列表,挨个检查每个槽位,跳过保留地址,找到能用的就分配:
func (b *allocationBlock) autoAssign(num int, handleID *string, affinityCfg AffinityConfig, attrs map[string]string, affinityCheck bool, reservations addrFilter) ([]cnet.IPNet, error) {
_, mask, _ := cnet.ParseCIDR(b.CIDR.String())
var ips []cnet.IPNet
updatedUnallocated := b.Unallocated[:0]
var attrIndexPtr *int
for idx, ordinal := range b.Unallocated {
// 已经够了,停止分配
if len(ips) >= num {
updatedUnallocated = append(updatedUnallocated, b.Unallocated[idx:]...)
break
}
// 检查是不是保留地址(比如网络地址、广播地址、节点保留地址等)
addr := b.OrdinalToIP(ordinal)
if reservations.MatchesIP(addr) {
log.WithField("addr", addr).Debug("Skipping reserved IP.")
updatedUnallocated = append(updatedUnallocated, ordinal)
continue
}
// 分配这个 IP
if attrIndexPtr == nil {
attrIndex := b.findOrAddAttribute(handleID, attrs)
attrIndexPtr = &attrIndex
}
b.Allocations[ordinal] = attrIndexPtr
ipNet := *mask
ipNet.IP = addr.IP
ips = append(ips, ipNet)
b.SetSequenceNumberForOrdinal(ordinal)
continue
}
b.Unallocated = updatedUnallocated
return ips, nil
}
分配完之后,calico 会把修改后的 IPAMBlock 写回 datastore(etcd 或者 k8s API),同时创建/更新对应的 IPAMHandle。这两个写操作也是用乐观锁保护的,如果 resourceVersion 对不上,说明有并发修改,重头来过。
常用的 IPAM 排查命令
实际排查问题时,以下这些命令比较常用:
# 查看 IP 池
calicoctl get ippool -o wide
# 查看所有 Block 的分配情况
calicoctl get ipamblock -o wide
# 查看某个节点拥有哪些 Block
calicoctl ipam show --show-blocks
# 查看具体的 IP 分配情况(需要指定 IP 池)
calicoctl ipam show --ip=192.168.1.5
# 检查 IPAM 的整体使用率
calicoctl ipam show
# 释放一个泄漏的 IP(谨慎操作)
calicoctl ipam release --ip=192.168.1.5
如果遇到 IP 分配失败的问题,通常先看一下 ipamblock 里有没有满的 Block 堆积在某个节点,再看看 ipamhandle 里有没有孤儿 handle(对应的 Pod 已经删了但 handle 还在)。后者是比较常见的 IP 泄漏场景,可以通过 calicoctl ipam check 来检测。