AI 以及 Agent 介绍
大语言模型(LLM)
大语言模型(Large Language Model,LLM)是指通过海量文本数据训练、具有数十亿乃至数千亿参数的神经网络模型,能够理解和生成自然语言文本。
有一点很关键:LLM 本身是无状态的。每次调用都是一次全新的推理,模型并不会自动记住你上一次说了什么。这就是为什么我们每次对话都需要把历史记录一并带上——把"记忆"作为输入传给模型,它才能结合上下文给出连贯的回复。
另外,LLM 也不只是一个聊天工具,它还可以用于文本分类、代码生成、信息抽取、摘要、翻译等各类 NLP 任务。
Prompt(提示词)
每次和大模型交互时,你输入的内容就叫做 Prompt(提示词)。Prompt 的质量对模型输出影响非常大,好的 Prompt 往往能让模型给出更准确、更有用的回答。
Prompt 通常分为几个部分:
- System Prompt:系统级别的指令,用来设定模型的角色和行为规范(比如"你是一个专业的法律助手")。
- User Message:用户发送的消息。
- Assistant Message:模型之前的回复,用于多轮对话中提供上下文。
Context(上下文)
Context(上下文)是指模型在生成回复时能"看到"的所有输入内容,包括历史对话、系统提示词、以及任何你额外传入的参考信息。
每个模型都有一个 Context Window(上下文窗口)的限制,也就是单次请求能处理的最大 Token 数量。超出这个范围的内容模型就看不见了。不同模型的上下文窗口差异较大,从早期的 4K tokens 到现在主流的 128K 甚至更长。
Memory(记忆)
我们说 LLM 是无状态的,但实际应用中通常需要它"记住"一些东西,这就引出了 Memory(记忆)的概念。
Memory 不只是把聊天记录原封不动地塞进去,它可以有多种形式:
- 短期记忆(Short-term Memory):就是当前对话的上下文窗口,随着会话结束而消失。
- 长期记忆(Long-term Memory):将重要信息持久化存储(比如数据库或向量数据库),下次对话时再按需检索。
- 记忆压缩:当对话历史太长、接近上下文窗口上限时,可以再调用一次大模型来对之前的内容做摘要,用更短的文本代替原始的聊天记录,从而节省 Token 消耗。
Agent(智能体)
大模型归根结底是一个文本输入、文本输出的系统。很多现实场景里,光靠"聊天"远远不够——有时候需要搜索互联网、读取本地文件、执行代码、操作数据库……这些都是纯文本模型做不到的事。
Agent(智能体)就是为了解决这个问题而出现的。它把大模型作为"大脑",通过调用各种外部工具来扩展模型的能力,从而完成更复杂的任务。
一个典型的 Agent 工作流大致是:接收用户请求 → 模型判断是否需要调用工具 → 调用工具获取结果 → 将结果返回给模型 → 模型生成最终回复。这个过程可以循环多次,直到任务完成。
Function Calling(函数调用)
有了工具,还得让模型知道"什么时候用哪个工具",这就是 Function Calling(函数调用)的作用。
简单来说,就是在发送请求时,把工具的定义(名称、功能描述、参数说明)一起传给模型。如果模型判断当前任务需要使用某个工具,它就会在输出中生成一段结构化的 JSON,告诉 Agent:“我现在需要调用这个函数,参数是这些”。Agent 解析这个 JSON 后执行对应的操作,再把结果喂回模型。
一个典型的工具定义长这样:
{
"name": "search_web",
"description": "Search the web for latest information",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Search query"
}
},
"required": ["query"]
}
}
模型在判断需要联网搜索时,就会生成一个调用 search_web 的请求,Agent 收到之后真正去执行搜索,再把结果作为新的上下文传回模型。
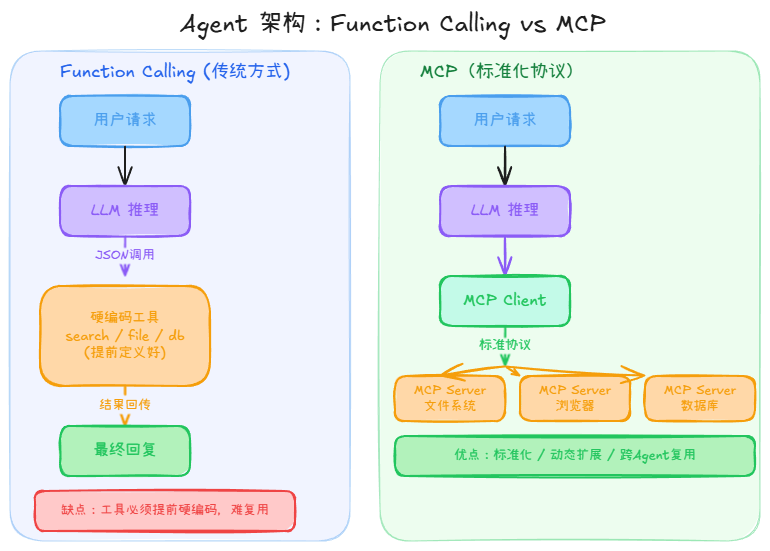
Function Calling 的局限性也很明显:所有工具必须提前定义好并硬编码在 Agent 中,不同 Agent 之间的工具很难复用,扩展起来也比较繁琐。
MCP(Model Context Protocol)
为了解决 Function Calling 的上述痛点,MCP(Model Context Protocol,模型上下文协议) 应运而生。
MCP 是一套用于连接大模型与外部工具、数据源和服务的标准通信协议,由 Anthropic 于 2024 年底提出并开源。它的核心思路是:把工具能力标准化,让模型通过统一的协议按需访问,而不是在每个 Agent 里各自重复实现。
如果用一句话来区分:
- Function Calling:模型调用提前硬编码好的函数。
- MCP:模型通过标准协议动态访问外部能力(工具、数据、服务)。
MCP 的整体架构由三个部分组成:
| 组件 | 职责 |
|---|---|
| MCP Client | 集成在 Agent 中,负责与 MCP Server 建立连接、发送请求 |
| MCP Server | 独立运行的服务,对外暴露具体的工具能力 |
| Model | 大语言模型,判断是否需要调用工具并生成调用请求 |
一次完整的工作流大致如下:
- 用户向 Agent 提问
- Agent 将问题发送给大模型
- 大模型判断是否需要使用工具
- 如果需要,通过 MCP Client 向 MCP Server 发起请求
- MCP Server 执行对应工具并返回结果
- Agent 将结果再次传给模型,生成最终答案
一个 MCP Server 暴露的工具列表示例:
{
"tools": [
{
"name": "search_web",
"description": "Search the internet for latest information"
},
{
"name": "read_file",
"description": "Read file from local filesystem"
},
{
"name": "run_command",
"description": "Execute shell command"
}
]
}
相比传统的 Function Calling,MCP 的优势在于:
- 标准化:所有工具都遵循同一套协议,降低接入成本。
- 动态扩展:随时可以新增 MCP Server,无需修改 Agent 核心代码。
- 跨 Agent 复用:一个 MCP Server 可以同时服务多个不同的 Agent。
- 生态丰富:开源社区已经出现了大量现成的 MCP Server,覆盖文件系统、浏览器、数据库、各类 SaaS 服务等场景。
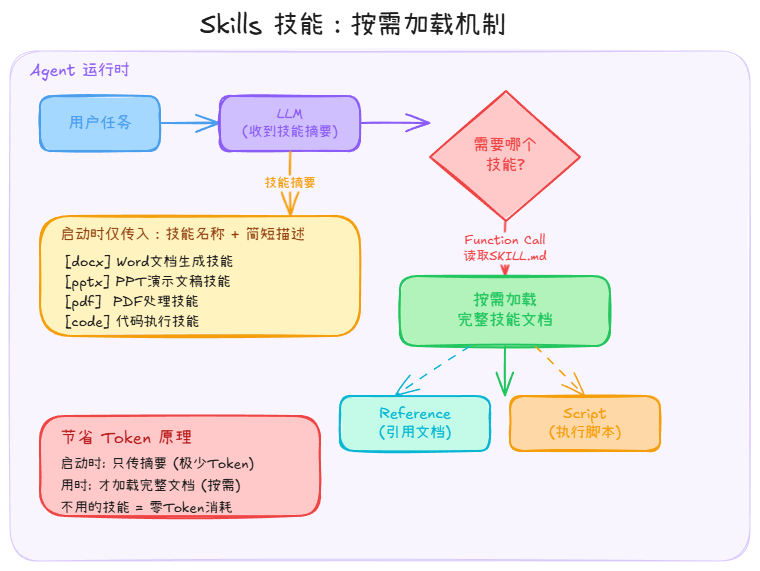
Skills(技能)
除了 Function Calling 和 MCP,Agent 还有一个常见的设计模式叫做 Skills(技能)。
Skills 的出现主要是为了节省 Token 消耗。
核心思路是这样的:把 Agent 的各类能力以文档的形式存放在固定目录下,每个技能对应一个文件夹,里面有说明文档(如 SKILL.md)。Agent 启动时,只把每个技能的名称和简短描述发给大模型,而不是一次性把所有技能文档的完整内容都塞进上下文——这样就省下了大量 Token。
当大模型判断某项任务需要某个具体技能时,它会通过 Function Calling 发出读取该技能文档的请求,Agent 才把对应的完整文档加载进上下文。这是一种典型的按需加载策略。
Skills 通常还包含两个子概念:
Reference(引用):技能文档中可以声明对其他文档的引用。当该技能被激活时,Agent 会自动把被引用文档的内容也一并加载进上下文,为模型提供更完整的参考信息。
Script(脚本):技能文档(或其 Reference)中可以声明需要执行的脚本。Agent 会调用命令执行工具来运行这些脚本,并将执行结果作为上下文信息回传给模型。
小结
说到底,Agent 的本质就是:反复调用大语言模型 + 在调用之间穿插执行本地或远程的工具操作。LLM 负责理解和推理,工具负责与真实世界交互,两者结合才能完成那些复杂的、需要多步骤的任务。没有什么神秘的魔法,理解了这个循环,Agent 的各种架构设计就都说得通了。